


SongGen: A Fully Open-Source Single-Stage Auto-Regressive Transformer Designed for Controllable Song Generation
www.marktechpost.com
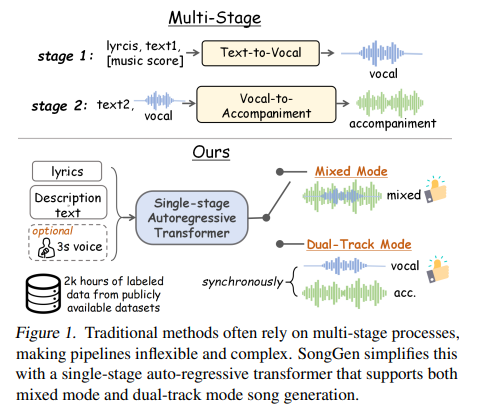
Creating songs from text is difficult because it involves generating vocals and instrumental music together. Songs are unique as they combine lyrics and melodies to express emotions, making the process more complex than generating speech or instrumental music alone. The challenge is intensified by the insufficient availability of quality open-source data, which restrains research and development in the area. Some approaches incorporate several steps, with vocals generated in the first place and the accompaniment generated separately. Such a method hinders the process of training and prediction and lessens the control of the final song. A major challenge is whether a single-step model can simplify this process while maintaining quality and flexibility.Currently, text-to-music generation models use descriptive text to create music, but most methods struggle to generate realistic vocals. Transformer-based models process audio as discrete tokens and diffusion models produce high-quality instrumental music, but both approaches face issues with vocal generation. Song generation, which combines vocals with instrumental music, relies on multi-stage methods like Jukebox, Melodist, and MelodyLM. These methods produce vocals and accompaniment independently, so the process is complicated and hard to manage. Without a common strategy, flexibility is restricted, and inefficiencies in training and inference are enhanced.To generate a song from text descriptions, lyrics, and optional reference voice, researchers proposed SongGen, an auto-regressive transformer decoder with an integrated neural audio codec. The model predicts audio token sequences, which are synthesized into songs. SongGen supports two generation modes: Mixed Mode and Dual-Track Mode. In Mixed Mode, X-Codec encodes raw audio into discrete tokens, with training loss emphasizing earlier codebooks to improve vocal clarity. A variant, Mixed Pro, introduces an auxiliary loss for vocals to enhance their quality. Dual-Track Mode separately generates vocals and accompaniment, synchronizing them through Parallel or Interleaving patterns. Parallel mode aligns tokens frame-by-frame, while Interleaving mode enhances interaction between vocals and accompaniment across layers.For conditioning, lyrics are processed using a VoiceBPE tokenizer, voice features are extracted via a frozen MERT encoder, and text attributes are encoded using FLAN-T5. These embeddings guide song generation via cross-attention. Due to the lack of public text-to-song datasets, an automated pipeline processes 8,000 hours of audio from multiple sources, ensuring quality data through filtering strategies.Researchers evaluated SongGen with Stable Audio Open, MusicGen, Parler-tts, and Suno for text-to-song generation. MusicGen produced only instrumental music, while Stable Audio Open generated unclear vocal sounds, and fine-tuning Parler-tts for singing proved ineffective. Despite using only 2,000 hours of labeled data, SongGen outperformed these models in text relevance and vocal control. Among its modes, the Mixed Pro approach enhanced vocal quality (VQ) and phoneme error rate (PER), while the Interleaving (A-V) dual-track method excelled in vocal quality but had slightly lower harmony (HAM). Attention analysis revealed that SongGen effectively captured musical structures. The model maintained coherence with minor performance drops even without a reference voice. Ablation studies confirmed that high-quality fine-tuning (HQFT), curriculum learning (CL), and VoiceBPE-based lyric tokenization improved stability and accuracy.In conclusion, the proposed model simplified text-to-song generation by introducing a single-stage, auto-regressive transformer that supported mixed and dual-track modes, demonstrating strong performance. Its open-source feature made it more accessible so that beginners and experts could produce music with precision control over voice and instrument components. However, the models capability to mimic voices is ethically problematic, calling for protection from abuse. As a foundational work in controllable text-to-song generation, SongGen can serve as a baseline for future research, guiding improvements in audio quality, lyric alignment, and expressive singing synthesis while addressing ethical and legal challenges.Check outthe Technical Details and GitHub Page.All credit for this research goes to the researchers of this project. Also,feel free to follow us onTwitterand dont forget to join our80k+ ML SubReddit. Divyesh Vitthal JawkhedeDivyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.Divyesh Vitthal Jawkhedehttps://www.marktechpost.com/author/divyesh-jawkhede/Optimizing Imitation Learning: How XIL is Shaping the Future of RoboticsDivyesh Vitthal Jawkhedehttps://www.marktechpost.com/author/divyesh-jawkhede/Sony Researchers Propose TalkHier: A Novel AI Framework for LLM-MA Systems that Addresses Key Challenges in Communication and RefinementDivyesh Vitthal Jawkhedehttps://www.marktechpost.com/author/divyesh-jawkhede/Meet Fino1-8B:A Fine-Tuned Version ofLlama 3.1 8B Instruct Designed to Improve Performance onFinancial Reasoning TasksDivyesh Vitthal Jawkhedehttps://www.marktechpost.com/author/divyesh-jawkhede/Ola: A State-of-the-Art Omni-Modal Understanding Model with Advanced Progressive Modality Alignment Strategy Recommended Open-Source AI Platform: IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System' (Promoted)
0 Commentarios
·0 Acciones
·65 Views