


Can 1B LLM Surpass 405B LLM? Optimizing Computation for Small LLMs to Outperform Larger Models
www.marktechpost.com
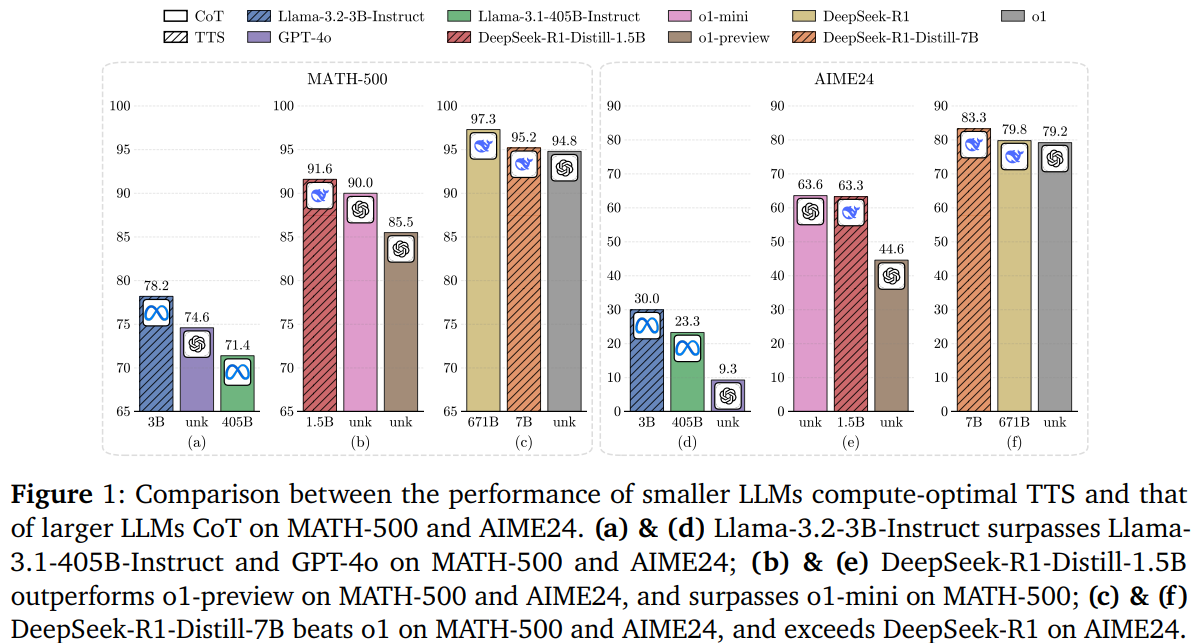
Test-Time Scaling (TTS) is a crucial technique for enhancing the performance of LLMs by leveraging additional computational resources during inference. Despite its potential, there has been little systematic analysis of how policy models, Process Reward Models (PRMs), and problem complexity influence TTS, limiting its practical application. TTS can be categorized into Internal TTS, which encourages step-by-step reasoning through extended Chain-of-Thought (CoT) processes, and External TTS, which enhances performance using sampling or search-based methods with fixed models. The key challenge in External TTS lies in optimizing computational allocation for different tasks. Current methods employ PRMs to guide answer selection and scale test-time computation efficiently. However, a comprehensive evaluation of how factors impact TTS strategies remains unexplored, restricting the communitys understanding of optimal computation scaling for LLMs.Prior research has explored multiple strategies to enhance LLM performance, including majority voting, search-based approaches, and self-refinement techniques. Test-time methods such as CoT prompting, self-verification, and external tool integration have proven effective in improving reasoning without modifying model parameters. PRMs, which outperform Output Reward Models (ORMs), significantly refine LLM-generated outputs. Recent advancements in PRMs focus on efficient data collection methods, implicit rewards, and advanced ranking techniques to improve mathematical reasoning. Tools like ProcessBench and PRMBench have been developed to facilitate benchmarking and evaluate PRM effectiveness. The evolution of PRMs and TTS strategies underscores the need for systematic research to optimize inference-time computation and enhance LLM capabilities across diverse tasks.Researchers from Shanghai AI Laboratory, Tsinghua University, Harbin Institute of Technology, and BUPT investigate the impact of policy models, PRMs, and problem complexity on TTS through extensive experiments on MATH-500 and AIME24 tasks. Their findings show that compute-optimal TTS strategies depend on these factors, allowing smaller models (e.g., 1B, 3B, 7B) to outperform larger ones (e.g., 405B, GPT-4o, DeepSeek-R1) with greater efficiency. The study emphasizes the importance of reward-aware TTS for optimal scaling, demonstrating that strategic test-time computation significantly enhances LLM reasoning abilities across different architectures and task complexities.Compute-optimal TTS optimally distributes computational resources for each problem. Prior approaches rely on PRMs as verifiers, either trained on the same policy model (on-policy) or a different one (offline). On-policy PRMs yield more accurate rewards, while offline PRMs face out-of-distribution challenges. Given the high cost of training PRMs per model, a general approach is needed. Experiments show that rewards significantly influence TTS performance. Thus, a reward-aware strategy is proposed, integrating rewards into compute allocation. Additionally, problem difficulty is better assessed using absolute thresholds rather than quantiles for more effective scaling strategies.The study examines the effectiveness of Compute-Optimal TTS in enhancing the performance of small policy models compared to larger ones. Experiments assess whether TTS allows smaller models to outperform larger ones, improve upon CoT and majority voting, and surpass long-CoT methods. Findings reveal that small models using compute-optimal TTS can outperform significantly larger models on MATH-500 and AIME24 tasks. TTS improves efficiency by up to 256 compared to majority voting and boosts reasoning by 154.6% over CoT. Moreover, TTS outperforms several long-CoT-based methods, demonstrating its effectiveness in enhancing LLM reasoning capabilities.In conclusion, the study examines compute-optimal TTS across various policy models, PRMs, and task complexities. Findings highlight that smaller models can surpass larger ones using optimized TTS, with a 1B model outperforming a 405B model. A 7B PRM also effectively supervises a 72B policy model, emphasizing a shift towards weak-to-strong supervision. Future work should focus on improving supervision methods for enhanced reasoning. While results are based on mathematical tasks, expanding TTS to coding and chemistry remains unexplored. These insights underscore TTSs potential to refine LLM efficiency and adaptability across diverse challenges.Check outthePaper and Project Page.All credit for this research goes to the researchers of this project. Also,feel free to follow us onTwitterand dont forget to join our75k+ ML SubReddit. Sana HassanSana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.Sana Hassanhttps://www.marktechpost.com/author/sana-hassan/Meet OpenThinker-32B: A State-of-the-Art Open-Data Reasoning ModelSana Hassanhttps://www.marktechpost.com/author/sana-hassan/Stanford Researchers Introduce SIRIUS: A Self-Improving Reasoning-Driven Optimization Framework for Multi-Agent SystemsSana Hassanhttps://www.marktechpost.com/author/sana-hassan/Frame-Dependent Agency: Implications for Reinforcement Learning and IntelligenceSana Hassanhttps://www.marktechpost.com/author/sana-hassan/Advancing Scalable Text-to-Speech Synthesis: Llasas Transformer-Based Framework for Improved Speech Quality and Emotional Expressiveness [Recommended] Join Our Telegram Channel
0 Comments
·0 Shares
·80 Views