

WWW.MARKTECHPOST.COM
Layer Parallelism: Enhancing LLM Inference Efficiency Through Parallel Execution of Transformer Layers
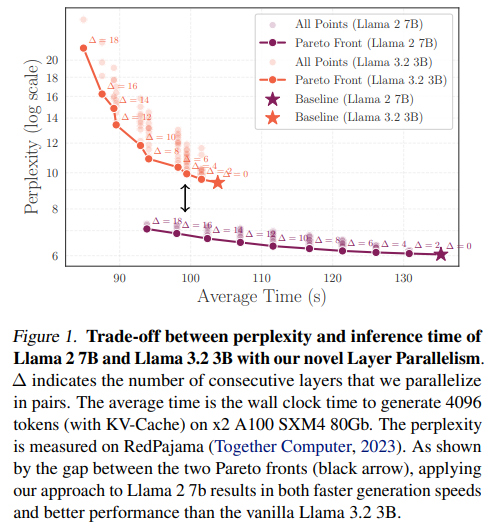
LLMs have demonstrated exceptional capabilities, but their substantial computational demands pose significant challenges for large-scale deployment. While previous studies indicate that intermediate layers in deep neural networks can be reordered or removed without severely impacting performance, these insights have not been systematically leveraged to reduce inference costs. Given the rapid expansion of LLMs, which often contain hundreds of billions of parameters, optimizing inference is critical for improving efficiency, reducing latency, and reducing operational expenses. High-traffic applications relying on cloud-based LLM inference can incur monthly costs in the millions, making efficiency-driven solutions essential. Furthermore, the ability to deploy these models on resource-constrained devices necessitates strategies that maintain performance while minimizing computational overhead. Despite architectural similarities between modern transformers and deep residual networks, where layer depth can sometimes be redundant, research has yet to explore these redundancies to fully optimize inference efficiency.Several approaches exist for improving the computational efficiency of LLMs, including pruning, quantization, and parallelization. Pruning eliminates redundant parameters to introduce sparsity, improving memory utilization and processing speed. On the other hand, Quantization reduces precision by converting floating-point computations to lower-bit integer formats like INT8 or INT4, enhancing hardware efficiency and energy savings. Additionally, parallelization techniques, such as tensor and pipeline parallelism, distribute workloads across multiple processing units to accelerate inference while addressing communication overhead. Recent innovations have also explored architectural modifications at the layer level, including layer fusion and dynamic recurrent execution, to streamline computational graphs. However, research has yet to focus on fusing consecutive layers through tensor parallelism, presenting an open avenue for optimizing inference further.Researchers from the University of Geneva, EPFL, and Meta FAIR propose a method to reduce the depth of pre-trained LLMs while preserving performance. Modifying the computational graph enables parallel execution of grouped layer pairs, improving inference speed by approximately 1.20 without requiring retraining. Their approach maintains 95%-99% accuracy across perplexity and In-Context Learning (ICL) benchmarks. Additionally, fine-tuning helps recover minor performance losses. This method significantly enhances efficiency for large-scale LLM deployment, demonstrating that structural transformations, such as layer merging and reordering, can optimize computational workload while sustaining model effectiveness.The study examines the effective depth of LLMs by applying transformations such as shuffling, merging, and pruning layers. Results indicate weak dependencies between intermediary layers, enabling certain layers to be reordered or parallelized with minimal perplexity loss. Running contiguous layers in parallel reduces depth while preserving performance, highlighting layer independence. Further, Layer Parallelism distributes computations across GPUs, optimizing efficiency through tensor parallelism. Modifications to attention and feed-forward networks ensure effective parallel execution. Adjustments to layer normalization help maintain stability. These findings suggest that transformer models can leverage parallelism to enhance computational efficiency without requiring substantial architectural modifications.The study evaluates layer parallelism regarding inference speed, ICL accuracy, and fine-tuning for performance recovery. Experiments use Llama2 7B and Llama3.2 3B on dual A100 GPUs. Layer Parallelism is applied to merged layers, with Tensor Parallelism elsewhere. Results show that beyond 14 layers for Llama2 7B and 10 for Llama3.2 3B, ICL accuracy declines. Speed improves proportionally, reaching a 1.38x boost at aggressive parallelism. Fine-tuning parallelized layers on RedPajama data significantly restores accuracy, improving MMLU from 83.6% to 94.4% while maintaining speed gains, demonstrating the viability of Layer Parallelism with targeted adjustments.In conclusion, the study introduces Layer Parallelism (LP), which restructures transformer computation by executing layer pairs in parallel, improving inference speed without retraining. Applied to Llama2 7B and Llama3.2 3B, LP reduced model depth by 21% and 18%, yielding speed-ups of 1.29x and 1.22x, respectively. Fine-tuning recovered 10.8% of lost accuracy, proving its effectiveness. These findings challenge the notion that transformer layers must process sequentially, suggesting selective parallelization is viable. LP enhances LLM efficiency in production, with future work exploring optimal layer grouping, interactions with quantization, and deeper theoretical insights into layer independence and computational efficiency.Check outthePaper.All credit for this research goes to the researchers of this project. Also,feel free to follow us onTwitterand dont forget to join our75k+ ML SubReddit. Sana HassanSana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.Sana Hassanhttps://www.marktechpost.com/author/sana-hassan/Can 1B LLM Surpass 405B LLM? Optimizing Computation for Small LLMs to Outperform Larger ModelsSana Hassanhttps://www.marktechpost.com/author/sana-hassan/Meet OpenThinker-32B: A State-of-the-Art Open-Data Reasoning ModelSana Hassanhttps://www.marktechpost.com/author/sana-hassan/Stanford Researchers Introduce SIRIUS: A Self-Improving Reasoning-Driven Optimization Framework for Multi-Agent SystemsSana Hassanhttps://www.marktechpost.com/author/sana-hassan/Frame-Dependent Agency: Implications for Reinforcement Learning and Intelligence [Recommended] Join Our Telegram Channel
0 Comments
0 Shares