


KGGen: Advancing Knowledge Graph Extraction with Language Models and Clustering Techniques
www.marktechpost.com
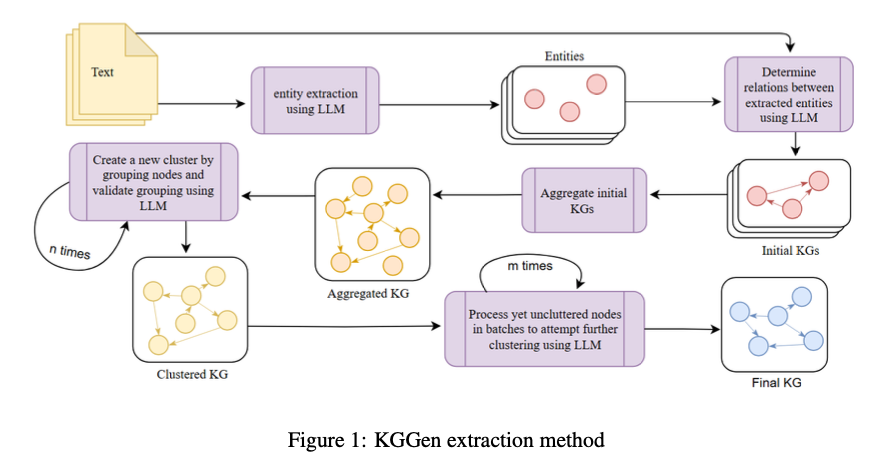
Knowledge graphs (KGs) are the foundation of artificial intelligence applications but are incomplete and sparse, affecting their effectiveness. Well-established KGs such as DBpedia and Wikidata lack essential entity relationships, diminishing their utility in retrieval-augmented generation (RAG) and other machine-learning tasks. Traditional extraction methods are likely to provide sparse graphs with absent important connections or noisy, redundant representations. Therefore it is difficult to obtain high-quality structured knowledge from unstructured text. Overcoming these challenges is critical to enable improved knowledge retrieval, reasoning, and insights with the help of artificial intelligence.State-of-the-art methods for extracting KGs from raw text are Open Information Extraction (OpenIE) and GraphRAG. OpenIE, a dependency parsing technique, produces structured (subject, relation, object) triples but produces extremely complex and redundant nodes, reducing coherence. GraphRAG, which combines graph-based retrieval and language models, enhances entity linking but does not produce densely connected graphs, restricting downstream reasoning processes. Both techniques are plagued by low entity resolution consistency, sparsity in connectivity, and poor generalizability, rendering them ineffective for high-quality KG extraction.Researchers from Stanford University, the University of Toronto, and FAR AI introduce KGGen, a novel text-to-KG generator that leverages language models and clustering algorithms to extract structured knowledge from plain text. Unlike earlier methods, KGGen introduces an iterative LM-based clustering method that enhances the extracted graph by merging synonymous entities and grouping relations. This enhances sparsity and redundancy, offering a more coherent and well-connected KG. KGGen also introduces MINE (Measure of Information in Nodes and Edges), the first benchmark for text-to-KG extraction performance, enabling standardized measurement of extraction methods.KGGen operates through a modular Python package with modules for entity and relation extraction, aggregation, and entity and edge clustering. The module for entity and relation extraction employs GPT-4o to obtain structured triples (subject, predicate, object) from unstructured text. The aggregation module combines extracted triples from different sources into a unified knowledge graph (KG), hence ensuring a homogeneous representation of entities. The module for entity and edge clustering uses an iterative clustering algorithm to disambiguate synonymous entities, cluster similar edges, and enhance graph connectivity. Through the enforcement of strict constraints on the language model using DSPy, KGGen enables the attainment of structured and high-fidelity extractions. The output knowledge graph is distinguished by its dense connectivity, semantic relevance, and optimization for artificial intelligence purposes.The benchmarking outcomes indicate the success of the method in extracting structured knowledge from text sources. KGGen gets an accuracy rate of 66.07%, which is significantly greater than GraphRAG at 47.80% and OpenIE at 29.84%. The system facilitates the capability to extract and structure knowledge without redundancy and enhancing connectivity and coherence. Comparative analysis confirms an 18% improvement in extraction fidelity over existing methods, highlighting its capability to generate well-structured knowledge graphs. Tests also demonstrate that produced graphs are denser and more informative, making them particularly suitable in the context of knowledge retrieval tasks and AI-based reasoning.KGGen is a breakthrough in the field of knowledge graph extraction because it pairs language model-based entity recognition with iterative clustering techniques to generate higher-quality structured data. By achieving radically improved accuracy on the MINE benchmark, it raises the bar for transforming unstructured text into impactful representations. This breakthrough has far-reaching implications for artificial intelligence-driven knowledge retrieval, reasoning operations, and embedding-based learning, thus paving the way for further development of larger and more comprehensive knowledge graphs. Future development will focus on refining clustering techniques and expanding benchmark tests to cover larger datasets.Check outthePaper.All credit for this research goes to the researchers of this project. Also,feel free to follow us onTwitterand dont forget to join our75k+ ML SubReddit. Aswin AkAswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.Aswin Akhttps://www.marktechpost.com/author/aswinak/ViLa-MIL: Enhancing Whole Slide Image Classification with Dual-Scale Vision-Language Multiple Instance LearningAswin Akhttps://www.marktechpost.com/author/aswinak/Mistral AI Introduces Mistral Saba: A New Regional Language Model Designed to Excel in Arabic and South Indian-Origin Languages such as TamilAswin Akhttps://www.marktechpost.com/author/aswinak/Higher-Order Guided Diffusion for Graph Generation: A Coarse-to-Fine Approach to Preserving Topological StructuresAswin Akhttps://www.marktechpost.com/author/aswinak/Can Users Fix AI Bias? Exploring User-Driven Value Alignment in AI Companions
0 Commenti
·0 condivisioni
·54 Views