


Meta AI Releases the Video Joint Embedding Predictive Architecture (V-JEPA) Model: A Crucial Step inAdvancing Machine Intelligence
www.marktechpost.com
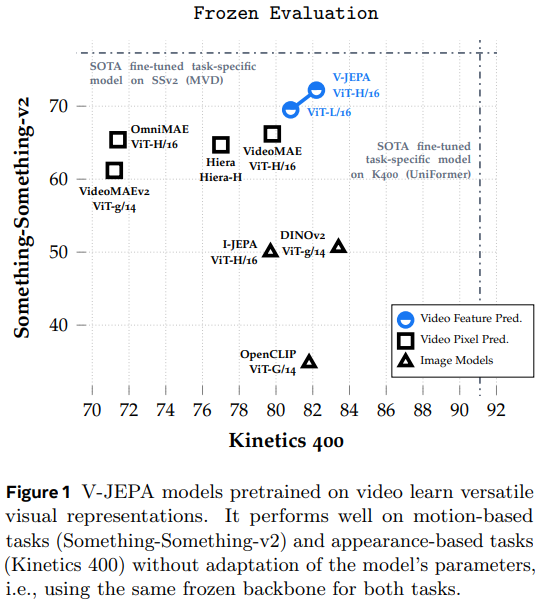
Humans have an innate ability to process raw visual signals from the retina and develop a structured understanding of their surroundings, identifying objects and motion patterns. A major goal of machine learning is to uncover the underlying principles that enable such unsupervised human learning. One key hypothesis, the predictive feature principle, suggests that representations of consecutive sensory inputs should be predictive of one another. Early methods, including slow feature analysis and spectral techniques, aimed to maintain temporal consistency while preventing representation collapse. More recent approaches incorporate siamese networks, contrastive learning, and masked modeling to ensure meaningful representation evolution over time. Instead of focusing solely on temporal invariance, modern techniques train predictor networks to map feature relationships across different time steps, using frozen encoders or training both the encoder and predictor simultaneously. This predictive framework has been successfully applied across modalities like images and audio, with models such as JEPA leveraging joint-embedding architectures to predict missing feature-space information effectively.Advancements in self-supervised learning, particularly through vision transformers and joint-embedding architectures, have significantly improved masked modeling and representation learning. Spatiotemporal masking has extended these improvements to video data, enhancing the quality of learned representations. Additionally, cross-attention-based pooling mechanisms have refined masked autoencoders, while methods like BYOL mitigate representation collapse without relying on handcrafted augmentations. Compared to pixel-space reconstruction, predicting in feature space allows models to filter out irrelevant details, leading to efficient, adaptable representations that generalize well across tasks. Recent research highlights that this strategy is computationally efficient and effective across domains like images, audio, and text. This work extends these insights to video, showcasing how predictive feature learning enhances spatiotemporal representation quality.Researchers from FAIR at Meta, Inria, cole normale suprieure, CNRS, PSL Research University, Univ. Gustave Eiffel, Courant Institute, and New York University introduced V-JEPA, a vision model trained exclusively on feature prediction for unsupervised video learning. Unlike traditional approaches, V-JEPA does not rely on pretrained encoders, negative samples, reconstruction, or textual supervision. Trained on two million public videos, it achieves strong performance on motion and appearance-based tasks without fine-tuning. Notably, V-JEPA outperforms other methods on Something-Something-v2 and remains competitive on Kinetics-400, demonstrating that feature prediction alone can produce efficient and adaptable visual representations with shorter training durations.The methodology involves training a foundation model for object-centric learning using video data. First, a neural network extracts object-centric representations from video frames, capturing motion and appearance cues. These representations are then refined through contrastive learning to enhance object separability. A transformer-based architecture processes these representations to model object interactions over time. The framework is trained on a large-scale dataset, optimizing for reconstruction accuracy and consistency across frames.V-JEPA is compared to pixel prediction methods using similar model architectures and shows superior performance across video and image tasks in frozen evaluation, except for ImageNet classification. With fine-tuning, it outperforms ViT-L/16-based models and matches Hiera-L while requiring fewer training samples. Compared to state-of-the-art models, V-JEPA excels in motion understanding and video tasks, training more efficiently. It also demonstrates strong label efficiency, outperforming competitors in low-shot settings by maintaining accuracy with fewer labeled examples. These results highlight the advantages of feature prediction in learning effective video representations with reduced computational and data requirements.In conclusion, the study examined the effectiveness of feature prediction as an independent objective for unsupervised video learning. It introduced V-JEPA, a set of vision models trained purely through self-supervised feature prediction. V-JEPA performs well across various image and video tasks without requiring parameter adaptation, surpassing previous video representation methods in frozen evaluations for action recognition, spatiotemporal action detection, and image classification. Pretraining on videos enhances its ability to capture fine-grained motion details, where large-scale image models struggle. Additionally, V-JEPA demonstrates strong label efficiency, maintaining high performance even when limited labeled data is available for downstream tasks.Check outthePaper and Blog.All credit for this research goes to the researchers of this project. Also,feel free to follow us onTwitterand dont forget to join our75k+ ML SubReddit. Sana HassanSana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.Sana Hassanhttps://www.marktechpost.com/author/sana-hassan/Meet Baichuan-M1: A New Series of Large Language Models Trained on 20T Tokens with a Dedicated Focus on Enhancing Medical CapabilitiesSana Hassanhttps://www.marktechpost.com/author/sana-hassan/xAI Releases Grok 3 Beta: A Super Advanced AI Model Blending Strong Reasoning with Extensive Pretraining KnowledgeSana Hassanhttps://www.marktechpost.com/author/sana-hassan/Learning Intuitive Physics: Advancing AI Through Predictive Representation ModelsSana Hassanhttps://www.marktechpost.com/author/sana-hassan/Microsoft AI Releases OmniParser V2: An AI Tool that Turns Any LLM into a Computer Use Agent
0 Comments
·0 Shares
·30 Views