


Optimizing Imitation Learning: How XIL is Shaping the Future of Robotics
www.marktechpost.com
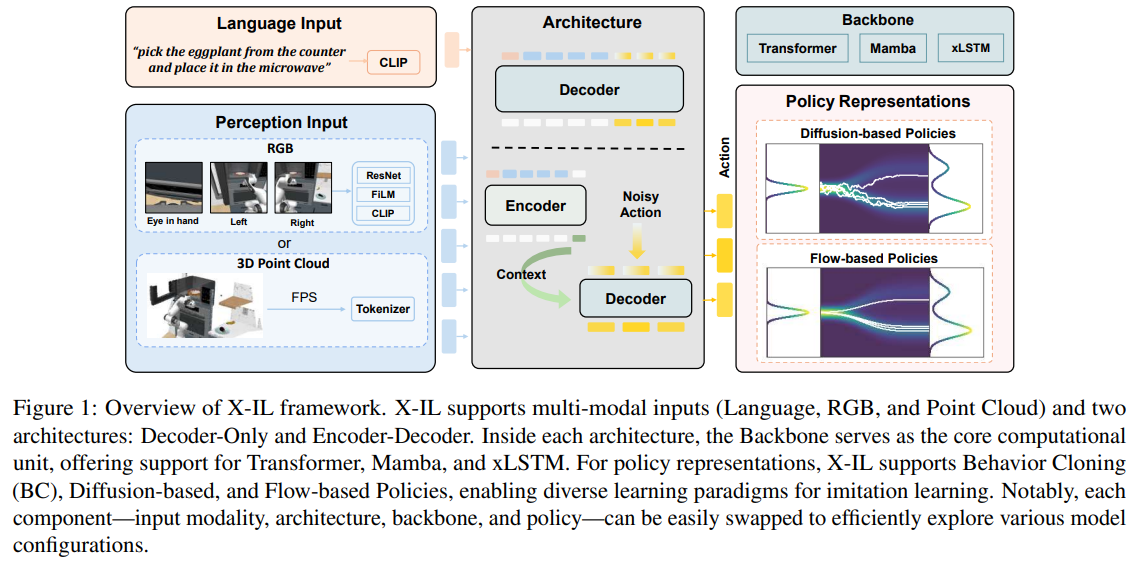
Designing imitation learning (IL) policies involves many choices, such as selecting features, architecture, and policy representation. The field is advancing quickly, introducing many new techniques and increasing complexity, making it difficult to explore all possible designs and understand their impact. IL enables agents to learn through demonstrations rather than reward-based approaches. The increasing number of machine-learning breakthroughs in various domains makes their assessment and integration into IL challenging. The space of IL design is underexplored, making creating effective and robust IL policies challenging.Currently, imitation learning is based on state-based and image-based methods, but both have limitations in practical use. State-based methods are inaccurate; image-based methods cannot represent 3D structures and have vague goal representation. Natural language has been added to enhance flexibility, but it is hard to incorporate it properly. Sequence models like RNNs suffer from vanishing gradients, making training inefficient, while Transformers offer better scalability. However, SSMs demonstrate higher efficiency but remain underutilized. Existing IL libraries do not support modern techniques like diffusion models, and tools such as CleanDiffuser are restricted to simple tasks, limiting overall progress in imitation learning.To mitigate these issues, researchers from Karlsruhe Institute of Technology, Meta and University of Liverpool proposed X-IL, an open-source framework for imitation learning that allows flexible experimentation with modern techniques. Unlike existing methods that struggle with integrating novel architectures, X-IL systematically divides the IL process into four key modules: observation representations, backbones, architectures, and policy representations. This module-based architecture facilitates effortless component swapping, with the possibility to test alternative learning strategies. Unlike conventional IL frameworks that are entirely based on state-based or image-based strategies, X-IL can incorporate multi-modal learning, using RGB images, point clouds, and language for more comprehensive representation learning. It also integrates advanced sequence modeling techniques like Mamba and xLSTM, which improve efficiency over Transformers and RNNs.The framework consists of interchangeable modules that allow customization at every stage of the IL pipeline. The observation module supports multiple input modalities, while the backbone module provides different sequence modeling approaches. Architectures consist of both decoder-only and encoder-decoder models with policy design flexibility. X-IL also optimizes policy learning by adopting diffusion-based and flow-based models, facilitating improved generalizability. Being capable of recent breakthroughs and enabling systematic assessment, X-IL is a scalable approach to effective IL model construction.Researchers evaluated imitation learning architectures for robotic tasks using the LIBERO and RoboCasa benchmarks. In LIBERO, models were trained on four task suites with 10 and 50 trajectories, where xLSTM achieved the highest success rates of 74.5% with 20% of the data and 92.3% with full data, indicating its effectiveness in learning from limited demonstrations. RoboCasa presented more challenges due to diverse environments, where xLSTM outperformed BC-Transformer with a 53.6% success rate, demonstrating its adaptability. Results indicated that combining RGB and point cloud inputs improved performance, with xLSTM achieving a 60.9% success rate. Encoder-decoder architectures outperformed decoder-only models, and fine-tuned ResNet encoders performed better than frozen CLIP models, highlighting the importance of strong feature extraction. Flow matching methods like BESO and RF demonstrated inference efficiency comparable to DDPM. In summary, the proposed framework provides a modular approach for exploring imitation learning policies across architectures, policy representations, and modalities. Supporting state-of-the-art encoders and efficient sequential models improves data efficiency and representation learning, achieving strong performance on LIBERO and RoboCasa. This framework can be a future research baseline, enabling policy design comparisons and advancing scalable imitation learning. Future work can refine encoders, integrate adaptive learning strategies, and enhance real-world generalization for diverse robotic tasks.Check outthe Paper.All credit for this research goes to the researchers of this project. Also,feel free to follow us onTwitterand dont forget to join our80k+ ML SubReddit. Divyesh Vitthal JawkhedeDivyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.Divyesh Vitthal Jawkhedehttps://www.marktechpost.com/author/divyesh-jawkhede/Sony Researchers Propose TalkHier: A Novel AI Framework for LLM-MA Systems that Addresses Key Challenges in Communication and RefinementDivyesh Vitthal Jawkhedehttps://www.marktechpost.com/author/divyesh-jawkhede/Meet Fino1-8B:A Fine-Tuned Version ofLlama 3.1 8B Instruct Designed to Improve Performance onFinancial Reasoning TasksDivyesh Vitthal Jawkhedehttps://www.marktechpost.com/author/divyesh-jawkhede/Ola: A State-of-the-Art Omni-Modal Understanding Model with Advanced Progressive Modality Alignment StrategyDivyesh Vitthal Jawkhedehttps://www.marktechpost.com/author/divyesh-jawkhede/How AI Chatbots Mimic Human Behavior: Insights from Multi-Turn Evaluations of LLMs Recommended Open-Source AI Platform: IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System' (Promoted)
0 Comentários
·0 Compartilhamentos
·37 Visualizações