


This AI Paper Introduces Agentic Reward Modeling (ARM) and REWARDAGENT: A Hybrid AI Approach Combining Human Preferences and Verifiable Correctness for Reliable LLM Training
www.marktechpost.com
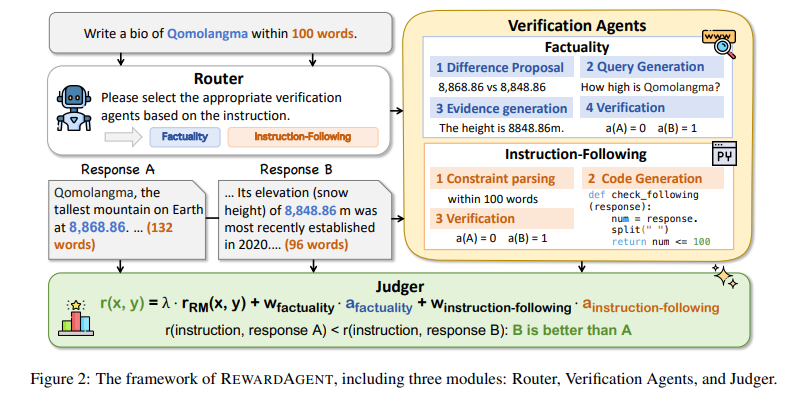
Large Language Models (LLMs) rely on reinforcement learning techniques to enhance response generation capabilities. One critical aspect of their development is reward modeling, which helps in training models to align better with human expectations. Reward models assess responses based on human preferences, but existing approaches often suffer from subjectivity and limitations in factual correctness. This can lead to suboptimal performance, as models may prioritize fluency over accuracy. Improving reward modeling with verifiable correctness signals can help enhance the reliability of LLMs in real-world applications.A major challenge in current reward modeling systems is their heavy reliance on human preferences, which are inherently subjective and prone to biases. These models favor verbose responses or those with appealing stylistic elements rather than objectively correct answers. The absence of systematic verification mechanisms in conventional reward models limits their ability to ensure correctness, making them vulnerable to misinformation. Moreover, instruction-following constraints are often ignored, leading to outputs that fail to meet precise user requirements. It is critical to address these issues to improve the robustness and reliability of AI-generated responses.Traditional reward models focus on preference-based reinforcement learning, such as Reinforcement Learning with Human Feedback (RLHF). While RLHF enhances model alignment, it does not incorporate structured correctness verification. Some existing models attempt to evaluate responses based on coherence and fluency but lack robust mechanisms for verifying factual accuracy or adherence to instructions. Alternative approaches, such as rule-based verification, have been explored but are not widely integrated due to computational challenges. These limitations highlight the need for a reward modeling system that combines human preferences with verifiable correctness signals to ensure high-quality language model outputs.Researchers from Tsinghua University introduced Agentic Reward Modeling (ARM), a novel reward system that integrates conventional preference-based reward models with verifiable correctness signals. The method incorporates a reward agent named REWARDAGENT, which enhances the reliability of rewards by combining human preference signals with correctness validation. This system ensures that LLMs generate responses that are both preferred by users and factually accurate. By integrating factual verification and instruction-following assessment, ARM provides a more robust reward modeling framework that reduces subjective biases and improves model alignment.The REWARDAGENT system consists of three core modules. The Router analyzes user instructions to determine which verification agents should be activated based on task requirements. The Verification Agents evaluate responses on two critical aspects: factual correctness and adherence to hard constraints. The factuality agent cross-checks information using both parametric knowledge and external sources, ensuring that responses are well-formed and factually grounded. The instruction-following agent ensures compliance with length, format, and content constraints by parsing specific instructions and verifying responses against predefined rules. The final module, Judger, integrates correctness signals and preference scores to compute an overall reward score, balancing subjective human feedback with objective verification. This architecture allows the system to dynamically select the most appropriate evaluation criteria for different tasks, ensuring flexibility and accuracy.Extensive experiments demonstrated that REWARDAGENT significantly outperforms traditional reward models. It was evaluated on benchmarks such as RM-Bench, JudgeBench, and IFBench, achieving superior performance in selecting factual and constraint-following responses. In RM-Bench, the model achieved a 76.0% accuracy score with a search engine and 79.3% without, compared to 71.4% from conventional reward models. The system was further applied in real-world best-of-n search tasks, where it improved response selection accuracy across multiple datasets, including TriviaQA, IFEval, and CELLO. On TriviaQA, REWARDAGENT achieved an accuracy of 68%, surpassing the base reward model ArmoRM. Further, the model was used to construct preference pairs for Direct Preference Optimization (DPO) training, where LLMs trained with REWARDAGENT-generated preference pairs outperformed those trained with conventional annotations. Specifically, models trained with this method showed improvements in factuality-based question-answering and instruction-following tasks, demonstrating its effectiveness in refining LLM alignment.The research addresses a crucial limitation in reward modeling by integrating correctness verification with human preference scoring. REWARDAGENT enhances the reliability of reward models and enables more accurate and instruction-adherent LLM responses. This approach paves the way for further research into incorporating additional verifiable correctness signals, ultimately contributing to developing more trustworthy and capable AI systems. Future work can expand the scope of verification agents to cover more complex correctness dimensions, ensuring that reward modeling continues to evolve with the increasing demands of AI-driven applications.Check outthe Paper and GitHub Page.All credit for this research goes to the researchers of this project. Also,feel free to follow us onTwitterand dont forget to join our80k+ ML SubReddit. NikhilNikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.Nikhilhttps://www.marktechpost.com/author/nikhil0980/This AI Paper from USC Introduces FFTNet: An Adaptive Spectral Filtering Framework for Efficient and Scalable Sequence ModelingNikhilhttps://www.marktechpost.com/author/nikhil0980/Transforming Speech Generation: How the Emilia Dataset Revolutionizes Multilingual Natural Voice SynthesisNikhilhttps://www.marktechpost.com/author/nikhil0980/How to Compare Two LLMs in Terms of Performance: A Comprehensive Web Guide for Evaluating and Benchmarking Language ModelsNikhilhttps://www.marktechpost.com/author/nikhil0980/Researchers from Moonshot AI Introduce Muon and Moonlight: Optimizing Large-Scale Language Models with Efficient Training Techniques Recommended Open-Source AI Platform: IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System' (Promoted)
0 التعليقات
·0 المشاركات
·61 مشاهدة