


LightThinker: Dynamic Compression of Intermediate Thoughts for More Efficient LLM Reasoning
www.marktechpost.com
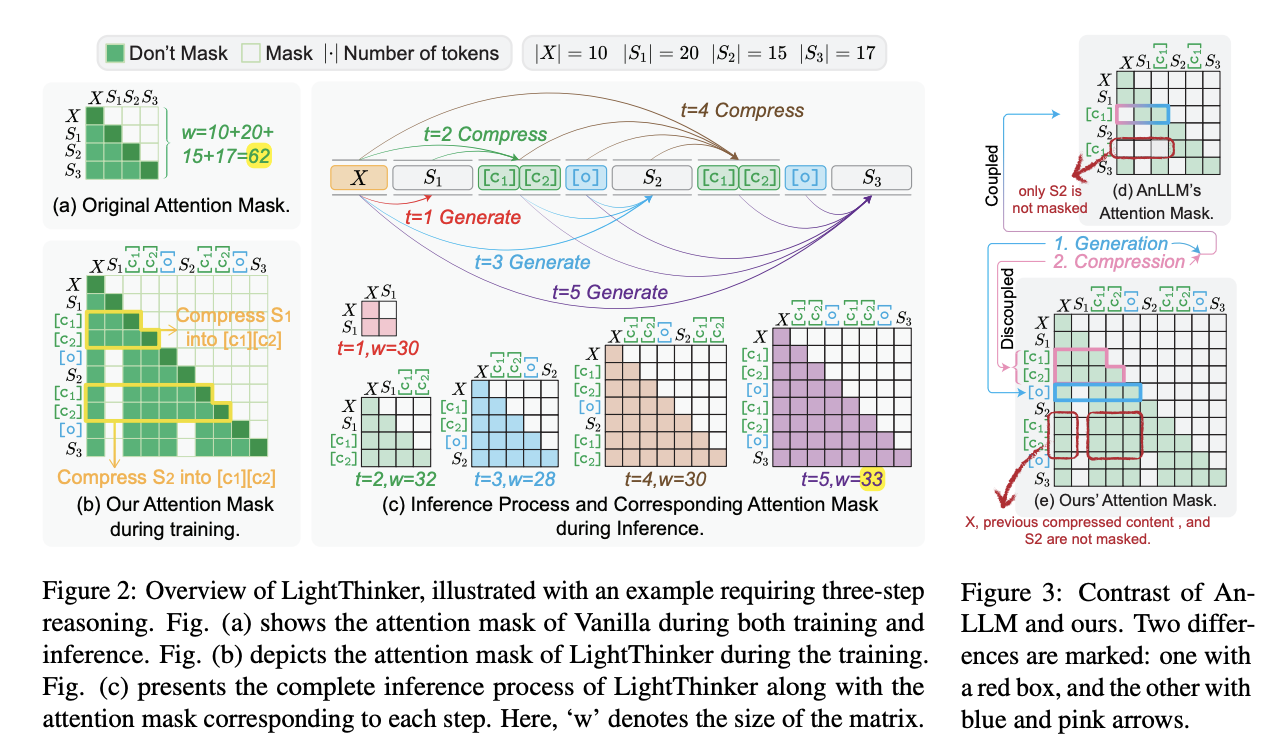
Methods like Chain-of-Thought (CoT) prompting have enhanced reasoning by breaking complex problems into sequential sub-steps. More recent advances, such as o1-like thinking modes, introduce capabilities, including trial-and-error, backtracking, correction, and iteration, to improve model performance on difficult problems. However, these improvements come with substantial computational costs. The increased token generation creates significant memory overhead due to the Transformer architectures limitations, where attention mechanism complexity grows quadratically with context length, while KV Cache storage increases linearly. For instance, when Qwen32Bs context length reaches 10,000 tokens, the KV Cache consumes memory comparable to the entire model.Current approaches to accelerate LLM inference fall into three main categories: Quantizing Model, Generating Fewer Tokens, and Reducing KV Cache. The quantizing model involves both parameter and KV Cache quantization techniques. Within the Reducing KV Cache category, pruning-based selection in discrete space and merging-based compression in continuous space emerge as key strategies. Pruning-based strategies implement specific eviction policies to retain only important tokens during inference. Merging-based strategies introduce anchor tokens that compress historically important information. The difference between these two methods is that Pruning-based methods are training-free but require applying eviction policies for every generated token, and Merging-based methods require model training.Researchers from Zhejiang University, Ant Group, and Zhejiang University Ant Group Joint Laboratory of Knowledge Graph have proposed LightThinker to enable LLMs to compress intermediate thoughts during reasoning dynamically. Inspired by human cognition, LightThinker compresses verbose reasoning steps into compact representations and discards original reasoning chains, significantly reducing the number of tokens stored in the context window. The researchers also introduce the Dependency (Dep) metric to quantify compression effectiveness by measuring reliance on historical tokens during generation. Moreover, the LightThinker reduces peak memory usage and inference time while maintaining competitive accuracy, offering a promising direction for enhancing LLM efficiency in complex reasoning tasks.The LightThinker approach is evaluated using the Qwen2.5-7B and Llama3.1-8B models. The researchers conducted full parameter instruction tuning using the Bespoke-Stratos-17k dataset, with the resulting model designated as Vanilla. Five comparison baselines were implemented: two training-free acceleration methods (H2O and SepLLM), one training-based method (AnLLM), and CoT prompting applied to both instruction and R1-Distill models. Evaluation occurred across four datasets (GSM8K, MMLU, GPQA, and BBH), measuring effectiveness and efficiency (via inference time, peak token count, and dependency metrics). The implementation features two compression approaches: token-level compression (converting every 6 tokens into 2) and thought-level compression (using \n\n as a delimiter to segment thoughts).Evaluation results across the four metrics for both models on all datasets reveal several significant findings. Distill-R1 consistently underperforms compared to CoT across all datasets, with the performance gap attributed to repetition issues caused by Greedy Decoding. H2O effectively preserves model performance while reducing memory usage, validating its greedy eviction policy for long-text generation. However, H2O substantially increases inference time (51% for Qwen and 72% for Llama) due to its token-wise eviction policy creating overhead for each generated token. Moreover, LightThinker matches H2Os performance with similar compression rates while reducing inference time with a 52% reduction for Qwen and 41% for Llama.In this paper, researchers introduced LightThinker, a novel approach to enhancing LLM efficiency in complex reasoning tasks through the dynamic compression of intermediate thoughts during generation. By training models to learn optimal timing and methods for compressing verbose reasoning steps into compact representations, LightThinker significantly reduces memory overhead and computational costs while maintaining competitive accuracy. However, several limitations remain: the compatibility with parameter-efficient fine-tuning methods like LoRA or QLoRA is unexplored, the potential benefits of larger training datasets are unknown, and performance degradation is notable on Llama series models when training on small datasets with next-token prediction.Check outthe Paper.All credit for this research goes to the researchers of this project. Also,feel free to follow us onTwitterand dont forget to join our80k+ ML SubReddit. Sajjad AnsariSajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.Sajjad Ansarihttps://www.marktechpost.com/author/sajjadansari/Meet AI Co-Scientist: A Multi-Agent System Powered by Gemini 2.0 for Accelerating Scientific DiscoverySajjad Ansarihttps://www.marktechpost.com/author/sajjadansari/Open-Reasoner-Zero: An Open-source Implementation of Large-Scale Reasoning-Oriented Reinforcement Learning TrainingSajjad Ansarihttps://www.marktechpost.com/author/sajjadansari/Optimizing Training Data Allocation Between Supervised and Preference Finetuning in Large Language ModelsSajjad Ansarihttps://www.marktechpost.com/author/sajjadansari/TokenSkip: Optimizing Chain-of-Thought Reasoning in LLMs Through Controllable Token Compression Recommended Open-Source AI Platform: IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System' (Promoted)
0 Σχόλια
·0 Μοιράστηκε
·81 Views