


Qilin: A Multimodal Dataset with APP-level User Sessions To Advance Search and Recommendation Systems
www.marktechpost.com
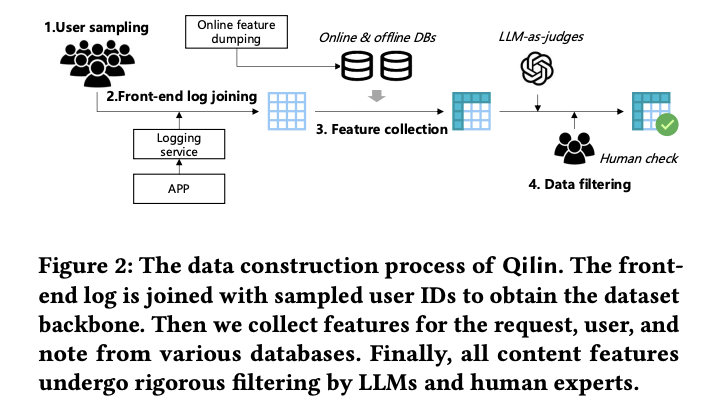
Search engines and recommender systems are essential in online content platforms nowadays. Traditional search methodologies focus on textual content, creating a critical gap in handling illustrated texts and videos that have become crucial components of User-Generated Content (UGC) communities. Current datasets for search and recommendation tasks contain textual information or statistically dense features, severely limiting the development of effective multimodal search and recommendation (S&R) services. Moreover, the session-level signal contains valuable contextual information about reformulating behavior, revisiting actions, search intent sources, and transition patterns between search and recommendation functionalities that directly impact user satisfaction and retention.Existing approaches tried to address multimodal retrieval challenges. Representation learning-based approaches map images into binary Hamming space using hash functions or encode them into latent semantic spaces with deep neural networks. Hash-aware methods provide efficient real-time performance with low storage costs, while semantic-based approaches focus on modality understanding and cross-modality matching. Moreover, the datasets for search, recommendation, and S&R tasks contain only textual contents or value-based features. While some e-commerce datasets include product titles and images and specialized datasets like UniIR and Flickr30K exist for multimodal retrieval, these address factoid queries with clear intent rather than complex user information needs.Researchers from Xiaohongshu Inc. and Tsinghua University have proposed Qilin, a multimodal information retrieval dataset designed to address the growing need for developing better S&R services. Collected from Xiaohongshu, a popular social platform with over 300 million monthly active users and an average search penetration rate exceeding 70%, this dataset offers a collection of user sessions with heterogeneous results, including image-text notes, video notes, commercial notes, and direct answers. Moreover, Qilin includes extensive APP-level contextual signals and genuine user feedback to better model user satisfaction and support the analysis of heterogeneous user behaviors. It uniquely contains user-favored answers and their referred results for search requests triggering the Deep Query Answering (DQA) module.Qilins dataset construction follows a pipeline that consists of user sampling, front-end log joining, feature collection, and data filtering. The dataset comprises APP-level sessions from 15,482 users, significantly larger and more diverse than existing search and recommendation datasets like Amazon, JD Search, and KuaiSAR. While Amazon can be marginally adopted for studying multimodal S&R systems, it only offers pseudo queries derived from product metadata, lacking real user search behaviors. JD Search and KuaiSAR provide only anonymized item contents, making model effectiveness interpretation difficult. Qilin addresses these limitations using Xiaohongshus open community platform with abundant UGC. After thorough filtering, the dataset includes original note content (title + main body + images), ensuring completeness and authenticity.Results for search and recommendation tasks show that the BERT cross-encoder outperforms the bi-encoder, confirming that explicit query and document interaction enhances relevance matching. Vision-Language Models (VLM) achieve even better performance by incorporating visual information. DCN-V2, which combines user history, sparse ID-based features, dense features, and pre-trained semantic embeddings, performs best in search ranking. However, its advantage is smaller in recommendation tasks for two reasons: the pseudo queries used in recommendation summarize user preferences, and recommendation requires greater model robustness to handle out-of-distribution problems. DCN-V2s dependence on sparse features and limited modeling of semantic signal matching may contribute to this performance gap.In conclusion, researchers introduced Qilin, a multimodal information retrieval dataset for search and recommendation research. Comprising APP-level sessions from 15,482 users, it provides textual and image content for heterogeneous results, addressing critical gaps in existing datasets. The researchers have collected abundant contextual signals, including query sources, multiple user feedback types, and deep query answering (DQA) details, creating a comprehensive framework for investigating various information retrieval tasks. Preliminary experiments in search, recommendation, and deep query answering on Qilin show its versatility and potential applications. These findings and insights provide valuable direction for developing more advanced multimodal retrieval systems.Check outthe Paper and Dataset on Hugging Face.All credit for this research goes to the researchers of this project. Also,feel free to follow us onTwitterand dont forget to join our80k+ ML SubReddit. Sajjad AnsariSajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.Sajjad Ansarihttps://www.marktechpost.com/author/sajjadansari/AxoNN: Advancing Large Language Model Training through Four-Dimensional Hybrid Parallel ComputingSajjad Ansarihttps://www.marktechpost.com/author/sajjadansari/LightThinker: Dynamic Compression of Intermediate Thoughts for More Efficient LLM ReasoningSajjad Ansarihttps://www.marktechpost.com/author/sajjadansari/Meet AI Co-Scientist: A Multi-Agent System Powered by Gemini 2.0 for Accelerating Scientific DiscoverySajjad Ansarihttps://www.marktechpost.com/author/sajjadansari/Open-Reasoner-Zero: An Open-source Implementation of Large-Scale Reasoning-Oriented Reinforcement Learning Training Recommended Open-Source AI Platform: IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System' (Promoted)
0 Commentaires
·0 Parts
·48 Vue