


This AI Paper Introduces R1-Searcher: A Reinforcement Learning-Based Framework for Enhancing LLM Search Capabilities
www.marktechpost.com
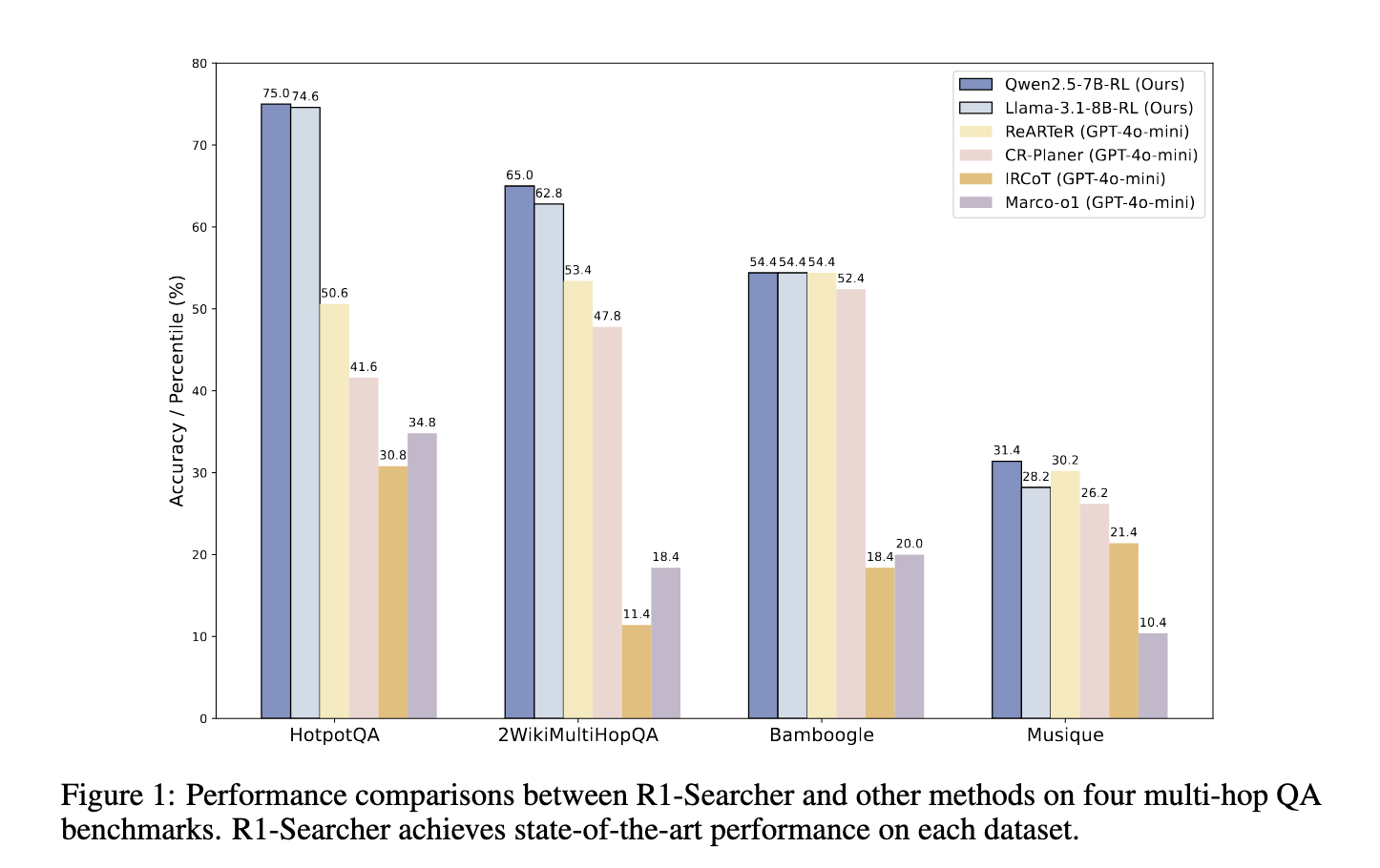
Large language models (LLMs) models primarily depend on their internal knowledge, which can be inadequate when handling real-time or knowledge-intensive questions. This limitation often leads to inaccurate responses or hallucinations, making it essential to enhance LLMs with external search capabilities. By leveraging reinforcement learning, researchers are actively working on methods to improve these models ability to retrieve and integrate relevant information beyond their static knowledge base.Current LLMs restricted access to up-to-date and domain-specific knowledge is a major issue. Since these models are trained on vast datasets that may not include recent developments, they struggle with answering dynamic questions requiring real-time information. While retrieval-augmented generation (RAG) methods have been introduced to mitigate this issue, existing solutions rely heavily on structured prompting and supervised fine-tuning (SFT). These approaches often lead to overfitting, limiting the models generalization ability across different datasets. There is a need for an alternative that allows LLMs to autonomously interact with external search systems, improving their adaptability and accuracy.Previous methods have attempted to incorporate external search functionality into LLMs using iterative prompting, supervised fine-tuning, and tree-based search techniques like Monte Carlo Tree Search (MCTS). While these methods show some improvements, they rely on expensive computational resources and proprietary models. Supervised fine-tuning, for instance, forces models to memorize reasoning paths, which negatively impacts their ability to generalize to new scenarios. Some retrieval-based strategies introduce multi-step query refinement techniques but often require human intervention or predefined prompt templates. These limitations necessitate the development of a more autonomous and efficient search mechanism for LLMs.A research team from the Renmin University of China and DataCanvas Alaya NeW introduced R1-Searcher, a novel reinforcement learning framework designed to improve LLMs ability to retrieve external knowledge effectively. This framework employs a two-stage reinforcement learning approach to enable LLMs to invoke an external search system without requiring human-crafted prompts or prior supervised fine-tuning. By focusing solely on reinforcement learning, R1-Searcher allows models to explore and learn optimal retrieval strategies autonomously, improving accuracy and efficiency in reasoning tasks.The R1-Searcher framework is structured in two phases. The first phase encourages the model to initiate external search actions, providing retrieval-based rewards without considering the final answers correctness. This phase ensures that the model learns to invoke search queries correctly. The second phase refines this capability by introducing an answer-based reward system, which evaluates whether the retrieved information contributes to solving the given problem. The reinforcement learning process relies on a tailored loss function that penalizes incorrect or unnecessary searches while rewarding the effective use of external knowledge. Unlike previous retrieval-based techniques, this approach allows LLMs to integrate reasoning and retrieval dynamically, improving their adaptability across diverse tasks.Experimental evaluations demonstrated that R1-Searcher outperformed existing retrieval-augmented methods, including GPT-4o-mini-based models. On the HotpotQA dataset, accuracy improved by 48.22%, while on the 2WikiMultiHopQA dataset, it achieved a 21.72% increase. Further, it showed strong generalization capabilities by outperforming other models on the Bamboogle dataset, achieving an 11.4% improvement over comparable retrieval-based approaches. Unlike previous techniques, which relied on closed-source models and extensive computational resources, R1-Searcher provided superior performance while maintaining efficiency in search and reasoning tasks. The study also demonstrated that this approach successfully mitigated common issues related to hallucinations and misinformation in LLM-generated responses.The findings indicate that enhancing LLMs with autonomous search capabilities can significantly improve their accuracy and generalization. Using reinforcement learning instead of supervised fine-tuning, R1-Searcher allows models to learn optimal retrieval strategies dynamically, eliminating reliance on memorized responses. This approach represents a major advancement in artificial intelligence, addressing the limitations of existing models while ensuring they remain adaptable to evolving knowledge requirements. The studys results highlight the potential for reinforcement learning to revolutionize knowledge integration in LLMs, making them more reliable for diverse reasoning tasks.Check outthe Paper and GitHub Page.All credit for this research goes to the researchers of this project. Also,feel free to follow us onTwitterand dont forget to join our80k+ ML SubReddit. NikhilNikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.Nikhilhttps://www.marktechpost.com/author/nikhil0980/This AI Paper Introduces RL-Enhanced QWEN 2.5-32B: A Reinforcement Learning Framework for Structured LLM Reasoning and Tool ManipulationNikhilhttps://www.marktechpost.com/author/nikhil0980/Visual Studio Code Setup GuideNikhilhttps://www.marktechpost.com/author/nikhil0980/This AI Paper Introduces CODI: A Self-Distillation Framework for Efficient and Scalable Chain-of-Thought Reasoning in LLMsNikhilhttps://www.marktechpost.com/author/nikhil0980/Getting Started with Kaggle Kernels for Machine Learning Parlant: Build Reliable AI Customer Facing Agents with LLMs (Promoted)
0 Commentarii
·0 Distribuiri
·51 Views