New approach from DeepMind partitions LLMs to mitigate prompt injection
In context: Prompt injection is an inherent flaw in large language models, allowing attackers to hijack AI behavior by embedding malicious commands in the input text. Most defenses rely on internal guardrails, but attackers regularly find ways around them – making existing solutions temporary at best. Now, Google thinks it may have found a permanent fix.
Since chatbots went mainstream in 2022, a security flaw known as prompt injection has plagued artificial intelligence developers. The problem is simple: language models like ChatGPT can't distinguish between user instructions and hidden commands buried inside the text they're processing. The models assume all entered (or fetched) text is trusted and treat it as such, which allows bad actors to insert malicious instructions into their query. This issue is even more serious now that companies are embedding these AIs into our email clients and other software that might contain sensitive information.
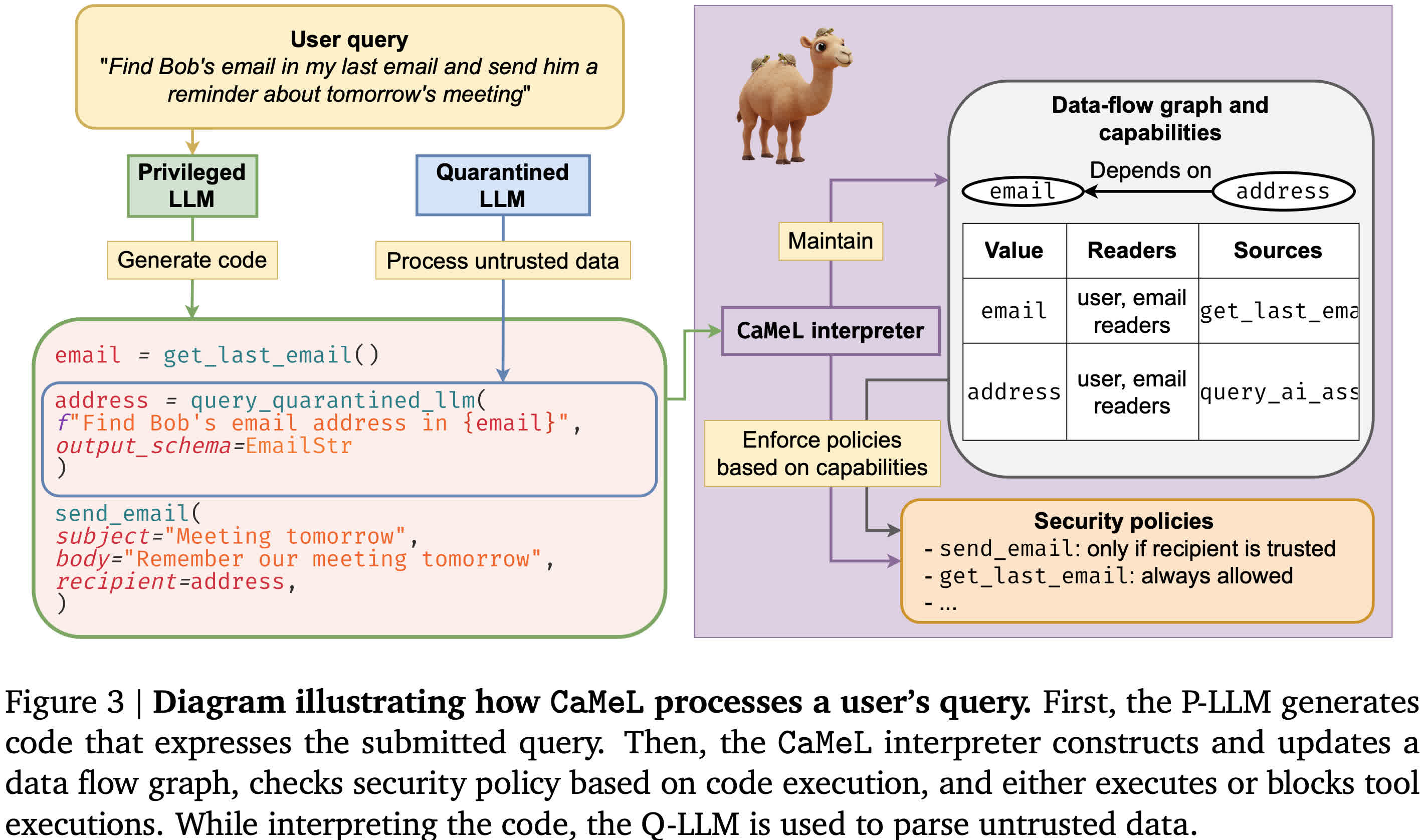
Google's DeepMind has developed a radically different approach called CaMeL (Capabilities for Machine Learning). Instead of asking artificial intelligence to self-police – which has proven unreliable – CaMeL treats large language models (LLMs) as untrusted components inside a secure system. It creates strict boundaries between user requests, untrusted content like emails or web pages, and the actions an AI assistant is allowed to take.
CaMeL builds on decades of proven software security principles, including access control, data flow tracking, and the principle of least privilege. Instead of relying on AI to catch every malicious instruction, it limits what the system can do with the information it processes.
Here's how it works. CaMeL uses two separate language models: a "privileged" one (P-LLM) that plans actions like sending emails, and a "quarantined" one (Q-LLM) that only reads and parses untrusted content. The P-LLM can't see raw emails or documents – it just receives structured data, like "email = get_last_email()." The Q-LLM, meanwhile, lacks access to tools or memory, so even if an attacker tricks it, it can't take any action.
All actions use code – specifically a stripped-down version of Python – and run in a secure interpreter. This interpreter traces the origin of each piece of data, tracking whether it came from untrusted content. If it detects that a necessary action involves a potentially sensitive variable, such as sending a message, it can block the action or request user confirmation.
Simon Willison, the developer who coined the term "prompt injection" in 2022, praised CaMeL as "the first credible mitigation" that doesn't rely on more artificial intelligence but instead borrows lessons from traditional security engineering. He noted that most current models remain vulnerable because they combine user prompts and untrusted inputs in the same short-term memory or context window. That design treats all text equally – even if it contains malicious instructions.
// Related Stories
CaMeL still isn't perfect. It requires developers to write and manage security policies, and frequent confirmation prompts could frustrate users. However, in early testing, it performed well against real-world attack scenarios. It may also help defend against insider threats and malicious tools by blocking unauthorized access to sensitive data or commands.
If you love reading the undistilled technical details, DeepMind published its lengthy research on Cornell's arXiv academic repository.