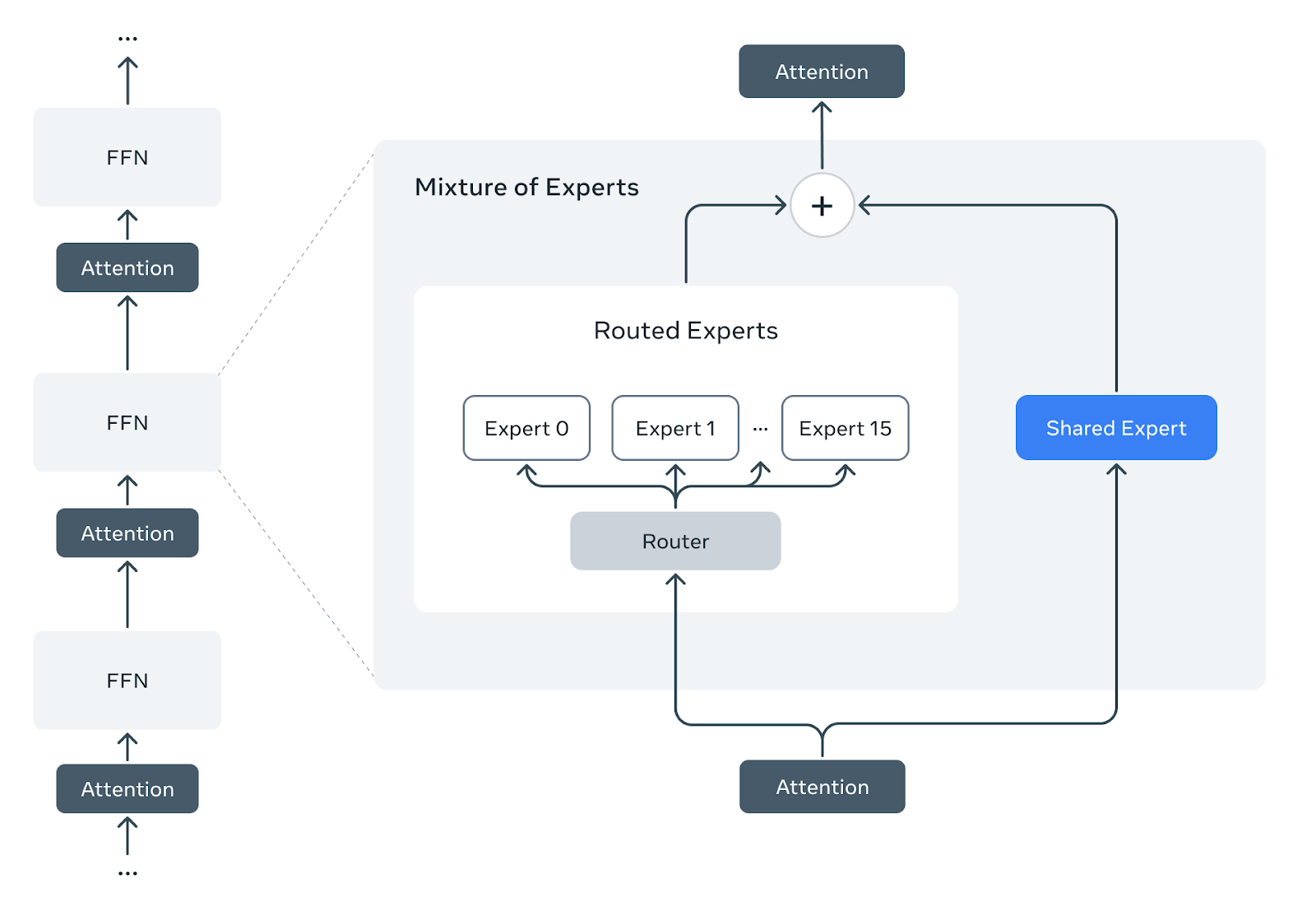
Exciting advancements in AI are on the horizon with the introduction of MetaShuffling for Llama 4 MoE inference! This innovative approach harnesses the power of Mixture-of-Experts (MoE) architecture to optimize large language models by activating only a select number of parameters per token. While this technique significantly enhances efficiency during training and inference, it also presents unique challenges that researchers are eager to tackle. The potential for faster and more effective language processing is immense, paving the way for smarter applications in our everyday lives. As we continue to push the boundaries of what AI can achieve, it's inspiring to see how innovations like MetaShuffling are shaping the future of technology! #AI #MachineLearning #Innovation #Llama4 #MetaShuffling
Exciting advancements in AI are on the horizon with the introduction of MetaShuffling for Llama 4 MoE inference! This innovative approach harnesses the power of Mixture-of-Experts (MoE) architecture to optimize large language models by activating only a select number of parameters per token. While this technique significantly enhances efficiency during training and inference, it also presents unique challenges that researchers are eager to tackle. The potential for faster and more effective language processing is immense, paving the way for smarter applications in our everyday lives. As we continue to push the boundaries of what AI can achieve, it's inspiring to see how innovations like MetaShuffling are shaping the future of technology! #AI #MachineLearning #Innovation #Llama4 #MetaShuffling