

WWW.MARKTECHPOST.COM
Meta AI Researchers Introduce Mixture-of-Transformers (MoT): A Sparse Multi-Modal Transformer Architecture that Significantly Reduces Pretraining Computational Costs
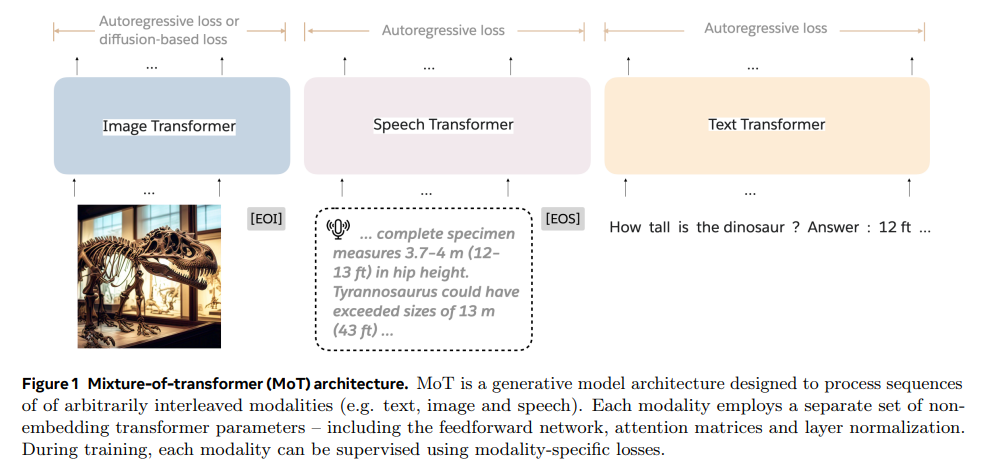
Advancements in AI have paved the way for multi-modal foundation models that simultaneously process text, images, and speech under a unified framework. These models can potentially transform various applications, from content creation to seamless translation across media types, as they enable the generation and interpretation of complex data. However, achieving this requires immense computational resources, which creates a barrier to scaling and operational efficiency. Training these multi-modal systems is complex, as each modality, whether text, image, or audio, introduces unique challenges, requiring customized handling while maintaining cohesion within the models framework. Balancing this level of diversity in data types has proven difficult regarding both processing power and training efficiency.A primary issue faced in multi-modal AI research is that traditional language models are optimized for text, and extending them to incorporate images and audio requires substantial computational power. Large language models, or LLMs, designed specifically for text-based tasks do not naturally integrate other modalities due to the inherent differences in how each modality needs to be processed. For instance, a text model optimized on trillions of tokens can only extend to image and speech data with conflicts in the training dynamics. Consequently, the computational load escalates, with these models requiring up to five times the data and processing power compared to text-only models. Researchers, therefore, aim to find architectures that can accommodate these requirements without a proportional increase in resources.Various strategies currently address this need for computational efficiency in multi-modal models. One prominent approach is using sparse architectures, such as Mixture-of-Experts (MoE), which activates only specific parts of the model as needed. MoE operates by utilizing experts to manage different aspects of the data, reducing the workload of the model at any given moment. However, MoE has limitations, including instability caused by unbalanced expert utilization and difficulty managing training dynamics at scale. Furthermore, MoEs routing mechanism tends to focus on specific aspects of the data, often leading to an imbalance in training different modalities, thus requiring additional techniques to stabilize the process and maintain efficiency.FAIR at Meta and Stanford University researchers introduced a new architecture called Mixture-of-Transformers (MoT). The MoT, built as a sparse, multi-modal transformer, reduces computational demands by incorporating modality-specific parameters. Unlike traditional dense models that rely on uniform processing, MoT utilizes distinct components for each modality, text, image, and speech, allowing for modality-specific optimization without requiring additional model components. For example, MoT assigns unique feed-forward networks, attention matrices, and normalization layers to each modality while maintaining a unified attention mechanism across the entire input data sequence, enhancing processing efficiency and output accuracy.The Mixture-of-Transformers framework leverages this sparse design by decoupling the model parameters according to modality, optimizing training and inference phases. For instance, MoT separates text, image, and speech parameters during a multi-modal task, applying customized processing layers for each. This process reduces the need for dense model layers to accommodate all modalities simultaneously. As a result, MoT achieves a balance of efficiency and effectiveness that traditional dense models lack. For instance, in tests involving text and image generation within the Chameleon 7B model, MoT delivered comparable results to dense baselines with only 55.8% of the FLOPs and even less 37.2% when integrating a third modality, such as speech. This efficiency gain translates to significant reductions in resource usage, which, in large-scale AI models, can lead to major cost savings.Mixture-of-Transformers showed notable improvements across multiple evaluation criteria. Compared to dense transformer models, the architecture reduced pretraining times for text and image tasks by over 40%. In the Chameleon setting, where the model processes text and images using autoregressive objectives, MoT reached the dense models final validation loss using just 55.8% of the computational power. Furthermore, MoT accelerated the training process by achieving the same levels of accuracy in image quality with 47.2% of the time required by dense models, and it achieved text quality in 75.6% of the typical time. Such efficiency gains were further confirmed in the Transfusion setting. MoT matched dense baseline image performance while using only one-third of the FLOPs, proving its adaptability and resource efficiency in handling complex multi-modal data.The research offers several key takeaways, highlighting the potential of Mixture-of-Transformers to redefine multi-modal AI processing:Efficient Multi-Modal Processing: MoT matches dense model performance across text, image, and speech, achieving results with 37.2% to 55.8% of the computational resources.Training Acceleration: In the Chameleon model, MoT reduced training time for image tasks by 52.8% and text tasks by 24.4% while maintaining accuracy.Adaptive Scalability: MoT demonstrated high adaptability by effectively handling discrete and continuous tokens for multiple modalities without additional processing layers.Resource Reduction in Real-Time Use: Performance evaluations on NVIDIA A100 GPUs showed MoT significantly reduced wall-clock training times, making it a viable option for real-time applications.In conclusion, Mixture-of-Transformers presents an innovative approach to multi-modal modeling by offering an efficient, scalable solution for integrating diverse data types within a single framework. Through a sparse architecture that leverages modality-specific processing, MoT significantly reduces computational load while delivering robust performance across various tasks. This breakthrough could transform the landscape of AI, enabling more accessible, resource-efficient models for advanced multi-modal applications.Check out the Paper. All credit for this research goes to the researchers of this project. Also,dont forget to follow us onTwitter and join ourTelegram Channel andLinkedIn Group. If you like our work, you will love ournewsletter.. Dont Forget to join our55k+ ML SubReddit. Asif RazzaqAsif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. Upcoming Live LinkedIn event, 'One Platform, Multimodal Possibilities,' where Encord CEO Eric Landau and Head of Product Engineering, Justin Sharps will talk how they are reinventing data development process to help teams build game-changing multimodal AI models, fast
0 Σχόλια
0 Μοιράστηκε
122 Views