


Unveiling Critical Batch Size Dynamics: How Data and Model Scaling Impact Efficiency in Large-Scale Language Model Training with Innovative Optimization Techniques
www.marktechpost.com
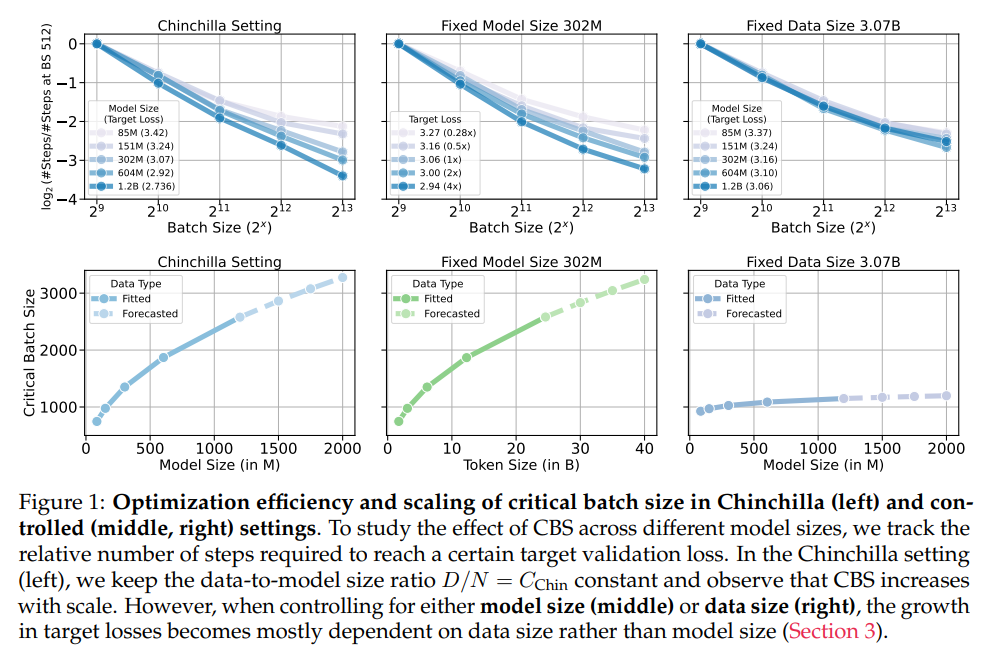
Large-scale model training focuses on improving the efficiency and scalability of neural networks, especially in pre-training language models with billions of parameters. Efficient optimization involves balancing computational resources, data parallelism, and accuracy. Achieving this requires a clear understanding of key metrics like the critical batch size (CBS), which plays a central role in training optimization. Researchers aim to uncover how to scale training processes effectively while maintaining computational efficiency and model performance.One of the primary challenges in training large-scale models is determining the point where increasing batch size no longer proportionally reduces optimization steps. This threshold, known as CBS, requires careful tuning to avoid diminishing returns in efficiency. Effective management of this trade-off is critical for enabling faster training within constrained resources. Practitioners without a clear understanding of CBS face difficulties scaling up training for models with higher parameter counts or larger datasets.Existing studies have explored the effects of batch size on model performance but often focus on achieving minimal loss rather than analyzing CBS explicitly. Also, most approaches need to separate the contributions of data size and model size to CBS, complicating the understanding of how these factors interact. Researchers have identified gaps in previous methodologies, particularly the need for a systematic framework to study CBS scaling for large-scale pre-training. This gap has hindered the development of optimized training protocols for larger models.The research from Harvard University, the University of California Berkeley, the University of Hong Kong, and Amazon addressed these gaps by introducing a systematic approach to measure CBS in large-scale autoregressive language models, with parameter sizes ranging from 85 million to 1.2 billion. The study utilized the C4 dataset comprising 3.07 billion tokens. The researchers performed extensive experiments to disentangle the effects of model size and data size on CBS. Scaling laws were developed to quantify these relationships, providing valuable insights into large-scale training dynamics.The experiments included training models under controlled scenarios, with either data or model size held constant to isolate their effects. This revealed that CBS is predominantly influenced by data size rather than model size. To refine their measurements, the researchers incorporated hyperparameter sweeps for learning rates and momentum. One key innovation was using exponential weight averaging (EWA), which improved optimization efficiency and ensured consistent performance across various training configurations.Notable findings included that CBS scales strongly with data size, allowing for greater data parallelism without sacrificing computational efficiency. For example, models trained with a fixed token count of 3.07 billion showed consistent CBS scaling regardless of parameter size. The study also demonstrated that increasing data size significantly reduces serial training time, highlighting the potential for optimizing parallelism in resource-constrained scenarios. The results align with theoretical analyses, including insights from infinite-width neural network regimes.The research established key takeaways that offer practical guidelines for large-scale training optimization. These are summarized as follows:Data size dominance: CBS scales primarily with data size, enabling efficient parallelism for larger datasets without degrading computational efficiency.Model size invariance: Increasing model size has minimal impact on CBS, particularly beyond a certain parameter threshold.Exponential weight averaging: EWA enhances training consistency and efficiency, outperforming traditional cosine scheduling in large-batch scenarios.Scaling strategies: Width and depth scaling yield equivalent efficiency gains, providing flexibility in model design.Hyperparameter tuning: Proper adjustments in learning rates and momentum are critical for achieving optimal CBS, especially in over- and under-training scenarios.In conclusion, this study sheds light on the critical factors influencing large-scale model training, with CBS emerging as a pivotal metric for optimization. The research provides actionable insights into enhancing training efficiency by demonstrating that CBS scales with data size rather than model size. Introducing scaling laws and innovative techniques like EWA ensures practical applicability in real-world scenarios, enabling researchers to design better training protocols for expansive datasets and complex models. These findings pave the way for more efficient use of resources in the rapidly evolving field of machine learning.Check out the Paper. All credit for this research goes to the researchers of this project. Also,dont forget to follow us onTwitter and join ourTelegram Channel andLinkedIn Group. If you like our work, you will love ournewsletter.. Dont Forget to join our55k+ ML SubReddit. Sana Hassan+ postsSana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions. Read this AI Research Report from Kili Technology on 'Evaluation of Large Language Model Vulnerabilities: A Comparative Analysis of Red Teaming Techniques'
0 Commentarios
·0 Acciones
·144 Views