Slim-Llama: An Energy-Efficient LLM ASIC Processor Supporting 3-Billion Parameters at Just 4.69mW
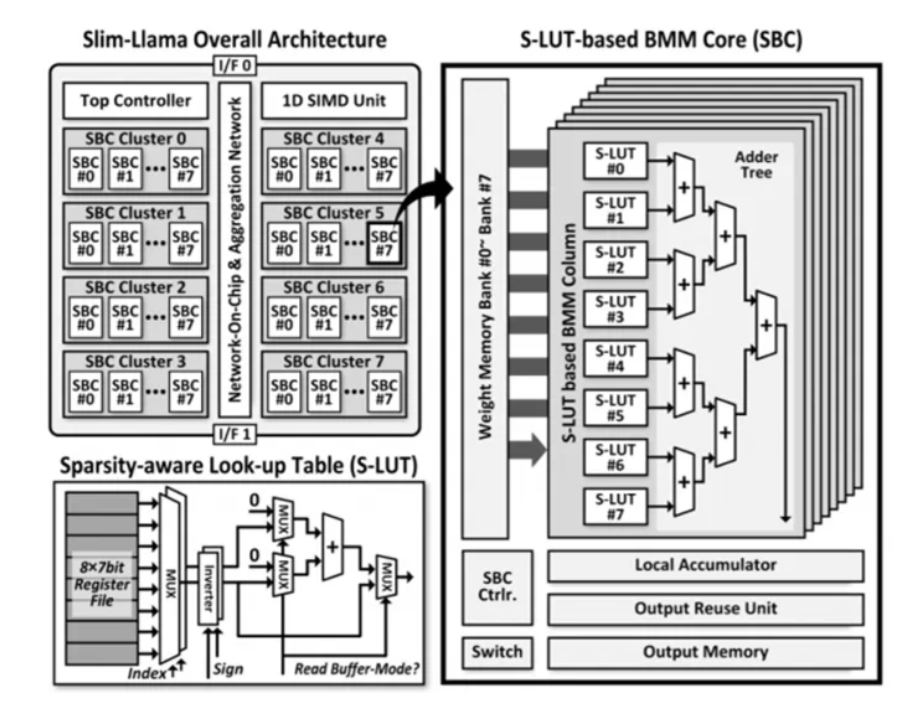
Large Language Models (LLMs) have become a cornerstone of artificial intelligence, driving advancements in natural language processing and decision-making tasks. However, their extensive power demands, resulting from high computational overhead and frequent external memory access, significantly hinder their scalability and deployment, especially in energy-constrained environments such as edge devices. This escalates the cost of operation while also limiting accessibility to these LLMs, which therefore calls for energy-efficient approaches designed to handle billion-parameter models.Current approaches to reduce the computational and memory needs of LLMs are based either on general-purpose processors or on GPUs, with a combination of weight quantization and sparsity-aware optimizations. Those have proven relatively successful in achieving some savings but are still heavily reliant on external memory which incurs significant energy overhead and fails to deliver the low-latency performance necessary for many real-time application runs. Such approaches are less well-suited to resource-constrained or sustainable AI systems.To address these limitations, researchers at the Korea Advanced Institute of Science and Technology (KAIST) developed Slim-Llama, a highly efficient Application-Specific Integrated Circuit (ASIC) designed to optimize the deployment of LLMs. This novel processor uses binary/ternary quantization to reduce the precision of model weights from real to 1 or 2 bits, thus minimizing significant memory and computational demands, leaving performance intact. This utilizes a Sparsity-aware Look-up Table or SLT that allows sparse data management. It employs output reuses and vector indexing with optimizations so that repeated procedure redundancy optimizes data flows. Thereby, this list of characteristics removes common limitations to achieve the typical method. They produce an energy-friendly scalable support mechanism for handling execution tasks within billions of LLMs.Slim-Llama is manufactured using Samsungs 28nm CMOS technology, with a compact die area of 20.25mm and 500KB of on-chip SRAM. This design removes all dependency on external memory; this is the only resource by which traditional systems are losing so much energy. Theres bandwidth support by it with up to 1.6GB/s in 200MHz frequencies so data management through this model is smooth as well as very efficient. Slim-Llama is capable of reaching a latency of 489 milliseconds using the Llama 1-bit model and supports models with up to 3 billion parameters, so it is well positioned for todays applications of artificial intelligence, which require both performance and efficiency. The most critical architectural innovations are binary and ternary quantization, sparsity-aware optimization, and efficient data flow management of which achieve major efficiency gains without compromising computational efficiency.The results highlight the high energy efficiency and performance capabilities of Slim-Llama. It achieves a 4.59x improvement in terms of energy efficiency over previous state-of-the-art solutions, whose power consumption ranges from 4.69mW at 25MHz to 82.07mW at 200MHz. The processor achieves a peak of 4.92 TOPS at an efficiency of 1.31 TOPS/W, addressing the critical requirement for energy-efficient hardware with large-scale AI models in place. Slim-Llama can process billion-parameter models with minimal latency, thus providing a promising candidate for real-time applications. A benchmark table, Energy Efficiency Comparison of Slim-Llama, illustrates the performance relative to the baseline systems in terms of power consumption, latency, and energy efficiency, with Slim-Llama achieving 4.92 TOPS and 1.31 TOPS/W, respectively, thus largely outperforming baseline hardware solutions.Slim-Llama is a new frontier in breaking through the energy bottlenecks of deploying LLMs. This scalable and sustainable solution combines novel quantization techniques, sparsity-aware optimization, and improvements in data flow to meet modern AI application needs. The proposed method is not only about efficiently deploying billion-parameter models but also opens the doors for more accessible and environmentally friendly AI systems by establishing a new benchmark for energy-efficient AI hardware.Check out the Technical Details. All credit for this research goes to the researchers of this project. Also,dont forget to follow us onTwitter and join ourTelegram Channel andLinkedIn Group. Dont Forget to join our60k+ ML SubReddit. Aswin Ak+ postsAswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges. [Download] Evaluation of Large Language Model Vulnerabilities Report (Promoted)