

WWW.MARKTECHPOST.COM
Google DeepMind Introduces FACTS Grounding: A New AI Benchmark for Evaluating Factuality in Long-Form LLM Response
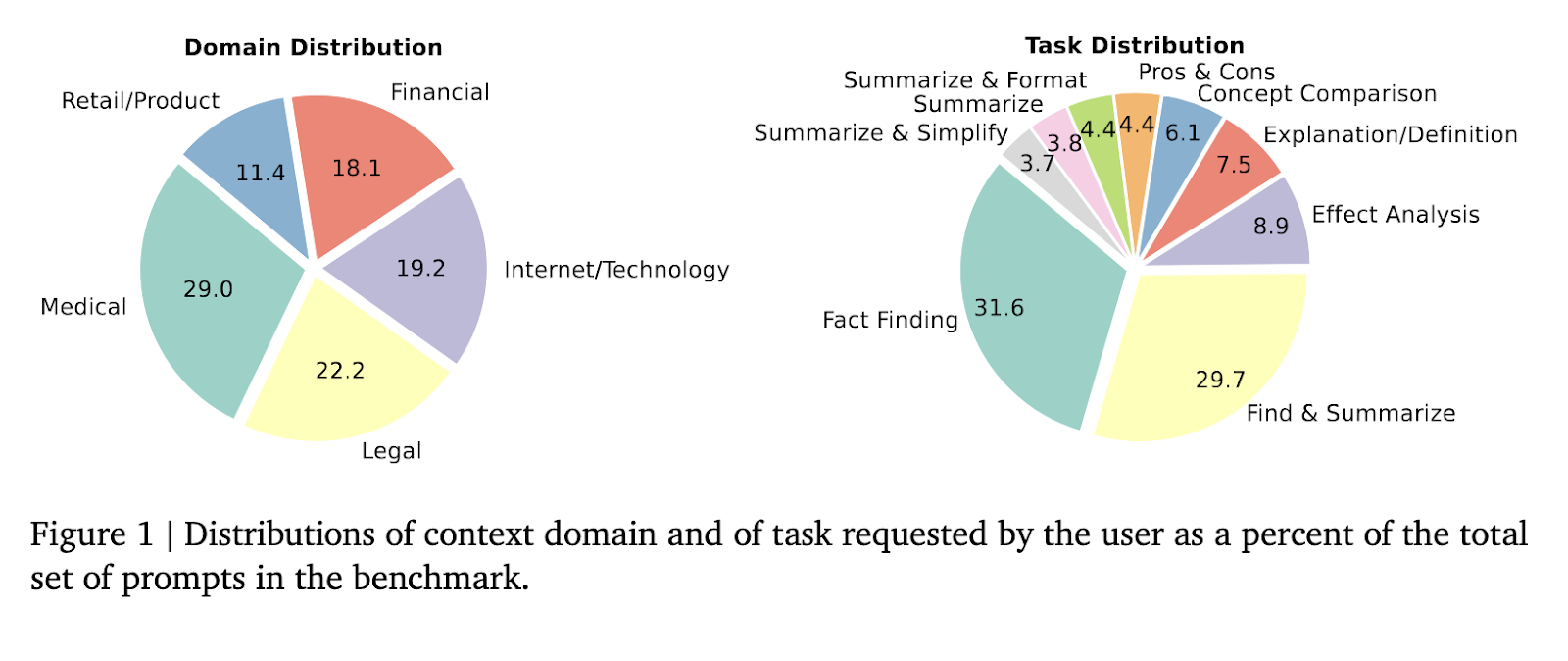
Despite the transformative potential of large language models (LLMs), these models face significant challenges in generating contextually accurate responses faithful to the provided input. Ensuring factuality in LLM outputs is particularly critical in tasks requiring responses grounded in lengthy, complex documents, which form the basis for advancing their applications in research, education, and industry.One major challenge in LLM development is their tendency to produce inaccurate or hallucinated content. This issue arises when models generate plausible-sounding text that is not supported by the input data. Such inaccuracies can have severe consequences, including the spread of misinformation and decreased trust in AI systems. Addressing this problem requires comprehensive benchmarks that evaluate the fidelity of LLM outputs to ensure that the generated text aligns strictly with the context provided in a prompt.Existing solutions to factuality challenges involve supervised fine-tuning and reinforcement learning. These methods aim to optimize LLMs to adhere more closely to factual content, albeit with limitations. Another approach leverages inference-time strategies like advanced prompting and model state interpretability to reduce inaccuracies. However, these techniques often result in trade-offs, compromising qualities such as creativity and response diversity. Consequently, there remains a need for a robust and scalable framework to systematically evaluate and enhance LLMs factuality without sacrificing other attributes.Researchers from Google DeepMind, Google Research, Google Cloud, and Kaggle introduced the FACTS Grounding Leaderboard to address these gaps. This benchmark is specifically designed to measure LLMs ability to generate responses fully grounded in extensive input contexts. The dataset includes user requests paired with source documents of up to 32,000 tokens, demanding responses that are factually correct and adhere strictly to the input context. The leaderboard is hosted on Kaggle and includes public and private data splits, encouraging broad participation while maintaining dataset integrity.The methodology underlying the FACTS Grounding benchmark involves a two-stage evaluation process. First, responses are screened for eligibility, disqualifying those failing to address user requests adequately. Eligible responses are then evaluated for factuality using multiple automated judge models, including Gemini 1.5 Pro, GPT-4o, and Claude 3.5 Sonnet. These models are prompted with optimized templates, ensuring high alignment with human judgment. For instance, the evaluation process uses span-level analysis to validate each claim in the response, with scores aggregated across multiple models to minimize bias. Further, the benchmark incorporates measures to prevent gaming of the scoring system, such as requiring comprehensive responses that directly address user queries.The FACTS Grounding Leaderboard revealed diverse performance results across tested models, showcasing the benchmarks rigor in evaluating factuality. Among the models evaluated, Gemini 1.5 Flash achieved an impressive factuality score of 85.8% in the public dataset, while Gemini 1.5 Pro and GPT-4o followed closely with scores of 84.9% and 83.6%, respectively. On the private dataset, Gemini 1.5 Pro outperformed others with a score of 90.7%. The disqualification of ineligible responses reduced scores by 1% to 5%, emphasizing the importance of robust filtering mechanisms. These results highlight the benchmarks ability to differentiate performance and promote transparency in model evaluation.The FACTS Grounding Leaderboard fills a critical gap in evaluating LLMs by focusing on long-form response generation. Unlike benchmarks emphasizing narrow use cases, such as short-form factuality or summarization, this benchmark addresses a broader spectrum of tasks, including fact-finding, document analysis, and information synthesis. By maintaining high evaluation standards and actively updating the leaderboard with new models, the initiative provides an essential tool for advancing the factual accuracy of LLMs.The research teams efforts underscore the importance of rigorous evaluation frameworks in overcoming the challenges associated with LLM-generated content. The FACTS Grounding benchmark provides a systematic approach to measuring factuality and fosters innovation in developing more reliable and accurate AI systems. This work sets a new standard for evaluating LLMs and inspires further advancements in artificial intelligence.Check out the Paper and Technical Details. All credit for this research goes to the researchers of this project. Also,dont forget to follow us onTwitter and join ourTelegram Channel andLinkedIn Group. Dont Forget to join our60k+ ML SubReddit. Nikhil+ postsNikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute. [Download] Evaluation of Large Language Model Vulnerabilities Report (Promoted)
0 Commentarios
0 Acciones
174 Views