ConfliBERT: A Domain-Specific Language Model for Political Violence Event Detection and Classification
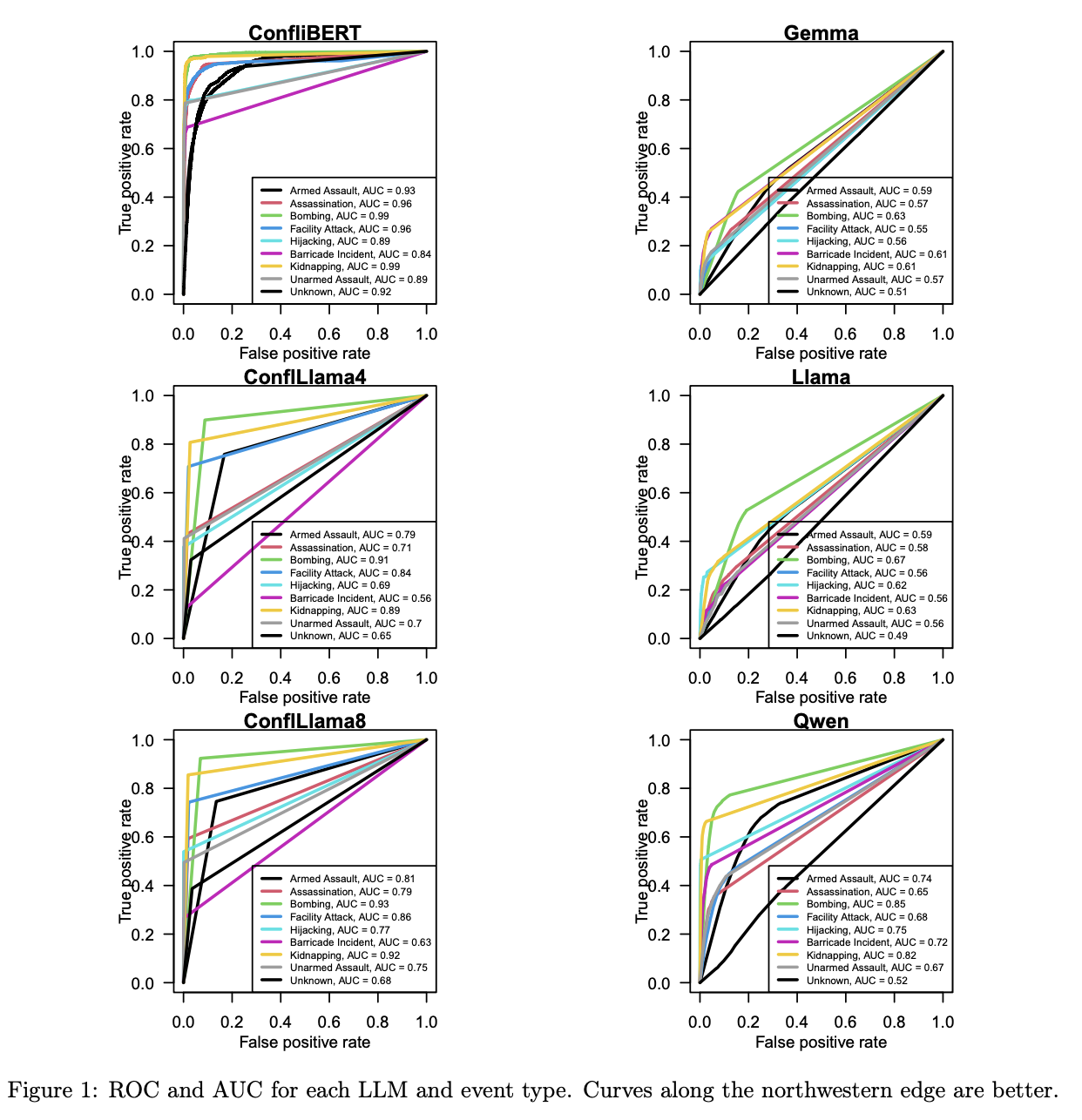
The transformation of unstructured news texts into structured event data represents a critical challenge in social sciences, particularly in international relations and conflict studies. The process involves converting large text corpora into who-did-what-to-whom event data, which requires extensive domain expertise and computational knowledge. While domain experts possess the knowledge to interpret these texts accurately, the computational aspects of processing large corpora require expertise in machine learning and natural language processing (NLP). This creates a fundamental challenge in effectively combining domain expertise with computational methodologies to achieve accurate and efficient text analysis.Various Large Language Models (LLMs) have attempted to address the challenge of event data extraction, each with distinct approaches and capabilities. Metas Llama 3.1, with 7 billion parameters, balances computational efficiency and performance, while Googles Gemma 2 (9 billion parameters) shows robust performance across NLP tasks. Alibabas Qwen 2.5 specializes in structured output generation, particularly JSON format. A notable development is ConfLlama, based on LLaMA-3 8B, which was fine-tuned on the Global Terrorism Database using QLoRA techniques. These models are evaluated using multiple performance metrics, including precision-recall and F1 scores for binary classification, and entity-level evaluations for Named Entity Recognition (NER) tasks.Researchers from UT Dallas, King Saud University, West Virginia University, and the University of Arizona have proposed ConfliBERT, a specialized language model designed for processing political and violence-related texts. This model has great capabilities in extracting actor, and action classifications from conflict-related textual data. Moreover, the method shows superior performance in accuracy, precision, and recall compared to LLMs like Googles Gemma 2, Metas Llama 3.1, and Alibabas Qwen 2.5 through extensive testing and fine-tuning. A notable advantage of ConfliBERT is its computational efficiency, operating hundreds of times faster than these general-purpose LLMs.ConfliBERTs architecture incorporates a complex fine-tuning approach that enhances the BERT representation through additional neural layer parameters, making it specifically adapted for conflict-related text analysis. The models evaluation framework focuses on its ability to classify terrorist attacks using the Global Terrorism Dataset (GTD), which was chosen for its comprehensive coverage, well-structured texts, and expert-annotated classifications. The model processes 37,709 texts to produce binary classifications across nine GTD event types. The evaluation methodology uses standard metrics including ROC, accuracy, precision, recall, and F1-scores, following established practices in conflict event classification.ConfliBERT achieves superior accuracy in basic classification tasks, particularly in identifying bombing and kidnapping events, which are the most common attack types. The models precision-recall curves consistently outperform other models, maintaining high performance at the northeastern edge of the plot. While the larger Qwen model approaches ConfliBERTs performance for specific event types like kidnappings and bombings, it doesnt match ConfliBERTs overall capabilities. Moreover, ConfliBERT excels in multi-label classification scenarios, achieving a subset accuracy of 79.38% and the lowest Hamming loss (0.035). The models predicted label cardinality (0.907) closely matches the true label cardinality (0.963), indicating its effectiveness in handling complex events with multiple classifications.In conclusion, researchers introduced ConfliBERT, which represents a significant advancement in NLP the application methods to conflict research and event data processing. The model integrates domain-specific knowledge with computational techniques and shows superior performance in text classification and summarization tasks compared to general-purpose LLMs. Potential areas for development include addressing challenges in continual learning and catastrophic forgetting, expanding ontologies to recognize new events and actors, extending text-as-data methods across different networks and languages, and strengthening the models capability to analyze complex political interactions and conflict processes while maintaining its computational efficiency.Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also,dont forget to follow us onTwitter and join ourTelegram Channel andLinkedIn Group. Dont Forget to join our60k+ ML SubReddit. Sajjad Ansari+ postsSajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner. [Download] Evaluation of Large Language Model Vulnerabilities Report (Promoted)