WWW.MARKTECHPOST.COM
Frenzy: A Memory-Aware Serverless Computing Method for Heterogeneous GPU Clusters
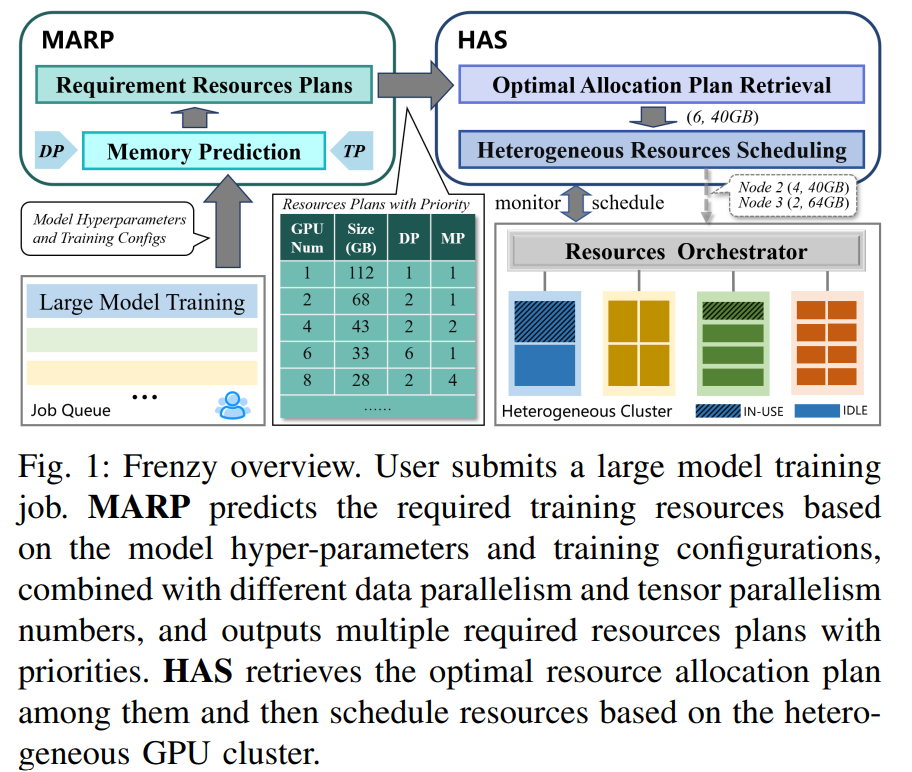
Artificial Intelligence (AI) has been making significant advances with an exponentially growing trajectory, incorporating vast amounts of data and building more complex Large Language Models (LLMs). Training these LLMs requires more computational power and resources for memory allocation, power usage, and hardware. Optimizing memory utilization for different types and configurations of GPUs is complex. Deciding the types and number of GPUs required for training a specific model has become an error-prone process for developers. Apart from that, different LLM tasks need to be efficiently scheduled across the heterogeneous GPUs.The complexity of the LLMs makes it impossible to guarantee that the utilization of the resources is efficient. To address these issues, a team of researchers have developed Frenzy, which automates resource allocation and scheduling.Traditional methods allocate GPU resources statically without adapting to dynamic memory requirements during training. Configurations must be done manually, which imparts only limited adaptability to the different types of GPUs and their memory capacities. This leads to suboptimal utilization of hardware resources, increasing training costs and time. Therefore, there is a need for a new approach to fight inefficient resource allocation, adapt to hardware heterogeneity, and raise the efficiency of complex LLMs.The proposed method, Frenzy, trains LLMs on heterogeneous GPU clusters. The key features of Frenzy include:Memory-Aware Resources Predictor (MARP): MARP can predict peak memory usage by analyzing the LLM architecture.Heterogeneity-Aware Scheduling (HAS): HAS distributes LLM tasks efficiently across different GPUs based on their memory capacity and computational power.Serverless Integration: Developers need not specify GPU requirements; this system can automatically do that.Dynamic Memory Optimization: The system continuously monitors memory usage, and bottlenecks are avoided by redistributing memory-intensive tasks.Experiments demonstrated that Frenzys memory usage prediction accuracy exceeds 92%. It reduced the scheduling overhead by 10 times compared to the traditional approaches. The average job completion time also decreased by 12% to 18%. Frenzy achieves superior resource allocation and adapts dynamically to GPU clusters.In summary, Frenzy tackles a critical bottleneck in training LLMs with a memory-aware, serverless system tailored for heterogeneous GPU clusters. Dynamic resource scheduling and memory-aware optimizations yield significant increases in efficiency, scalability, and cost-effectiveness. This research represents a stride toward sustainable and scalable LLM training solutions by offering a robust framework for effectively harnessing heterogeneous GPU clusters. Frenzys adaptability and high performance set a new landmark in LLM training and opened up broader adoption in research and industry.Check out the Paper. All credit for this research goes to the researchers of this project. Also,dont forget to follow us onTwitter and join ourTelegram Channel andLinkedIn Group. Dont Forget to join our60k+ ML SubReddit. Afeerah Naseem+ postsAfeerah Naseem is a consulting intern at Marktechpost. She is pursuing her B.tech from the Indian Institute of Technology(IIT), Kharagpur. She is passionate about Data Science and fascinated by the role of artificial intelligence in solving real-world problems. She loves discovering new technologies and exploring how they can make everyday tasks easier and more efficient. [Download] Evaluation of Large Language Model Vulnerabilities Report (Promoted)