WWW.MARKTECHPOST.COM
Meet Search-o1: An AI Framework that Integrates the Agentic Search Workflow into the o1-like Reasoning Process of LRM for Achieving Autonomous Knowledge Supplementation
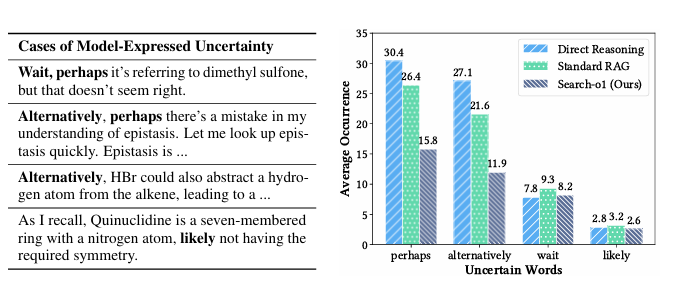
Large reasoning models are developed to solve difficult problems by breaking them down into smaller, manageable steps and solving each step individually. The models use reinforcement learning to enhance their reasoning abilities and develop very detailed and logical solutions. However, while this method is effective, it has its challenges. Overthinking and error in missing or insufficient knowledge result from the extended reasoning process. Gaps in understanding may disrupt the entire reasoning chain, making it harder to arrive at accurate conclusions.Traditional methods in large reasoning models aim to enhance performance by increasing model size or expanding training data during the training phase. While test-time scaling shows potential, current approaches rely heavily on static, parameterized models that cannot utilize external knowledge when internal understanding is insufficient. Techniques like policy-reward combinations with Monte Carlo Tree Search, deliberate error integration, and data distillation improve reasoning but fail to internalize or adapt reasoning abilities fully. Retrieval-augmented generation (RAG) systems address some limitations by incorporating external knowledge retrieval but struggle to integrate the strong reasoning capabilities seen in advanced models. These gaps limit the ability to solve complex, knowledge-intensive tasks effectively.To solve the challenge of multi-step reasoning tasks requiring external knowledge, researchers from the Renmin University of China and Tsinghua University proposed the Search-o1 framework. The framework integrates task instructions, questions, and dynamically retrieved knowledge documents into a coherent reasoning chain to derive logical solutions and answers. Unlike traditional models that struggle with missing knowledge, Search-o1 extends the retrieval-augmented generation mechanism by including a Reason-in-Documents module. This module condenses lengthy retrieved information into precise steps, ensuring a logical flow. The iterative process continues until a complete reasoning chain and final answer are formed.The framework was compared with vanilla reasoning and basic retrieval-augmented methods. Vanilla reasoning often fails when knowledge gaps arise, while basic augmented methods retrieve overly detailed and redundant documents, disrupting reasoning coherence. The Search-o1 framework avoids these by creating searches on the fly whenever required, extracting documents, and transforming them into clear and related reasoning steps. The agentic mechanism is another feeder that guarantees appropriate knowledge integration, and the Reason-in-Documents proved to be coherent, hence keeping the reasoning quite accurate and stable.Researchers evaluated the framework on two categories of tasks: challenging reasoning tasks and open-domain question-answering (QA) tasks. The challenging reasoning tasks included GPQA, a PhD-level science multiple-choice QA dataset; mathematical benchmarks such as MATH500, AMC2023, and AIME2024; and LiveCodeBench to assess coding capabilities. The open-domain QA tasks were tested using datasets like Natural Questions (NQ), TriviaQA, HotpotQA, 2WikiMultihopQA, MuSiQue, and Bamboogle. The evaluation involved comparisons with baseline methods, including direct reasoning approaches, retrieval-augmented reasoning, and the Search-o1 framework proposed by the researchers. Tests were conducted under varying conditions using a consistent setup, which included the QwQ32B-Preview model as the backbone and the Bing Web Search API for retrieval.Results showed that QwQ-32B-Preview excelled across reasoning tasks, surpassing larger models like Qwen2.5-72B and Llama3.3-70B. Search-o1 outperformed retrieval-augmented approaches like RAgent-QwQ-32B with notable coherence and knowledge integration gains. For example, on average, Search-o1 exceeded RAgent-QwQ-32B and QwQ-32B by 4.7% and 3.1%, respectively, and achieved a 44.7% improvement over smaller models like Qwen2.5-32B. Comparisons with human experts on the GPQA extended set revealed Search-o1s superiority in integrating reasoning strategies, particularly in science-related tasks.In conclusion, the proposed framework addressed the problem of knowledge inadequacy in large reasoning models by combining retrieval-augmented generation with a Reason-in-Documents module to allow better use of external knowledge. This framework can be a baseline for future research to enhance retrieval systems, document analysis, and intelligent problem-solving across complex domains.Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also,dont forget to follow us onTwitter and join ourTelegram Channel andLinkedIn Group. Dont Forget to join our65k+ ML SubReddit. Divyesh Vitthal Jawkhede+ postsDivyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges. [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)