

WWW.MARKTECHPOST.COM
Google AI Introduces Learn-by-Interact: A Data-Centric Framework for Adaptive and Efficient LLM Agent Development
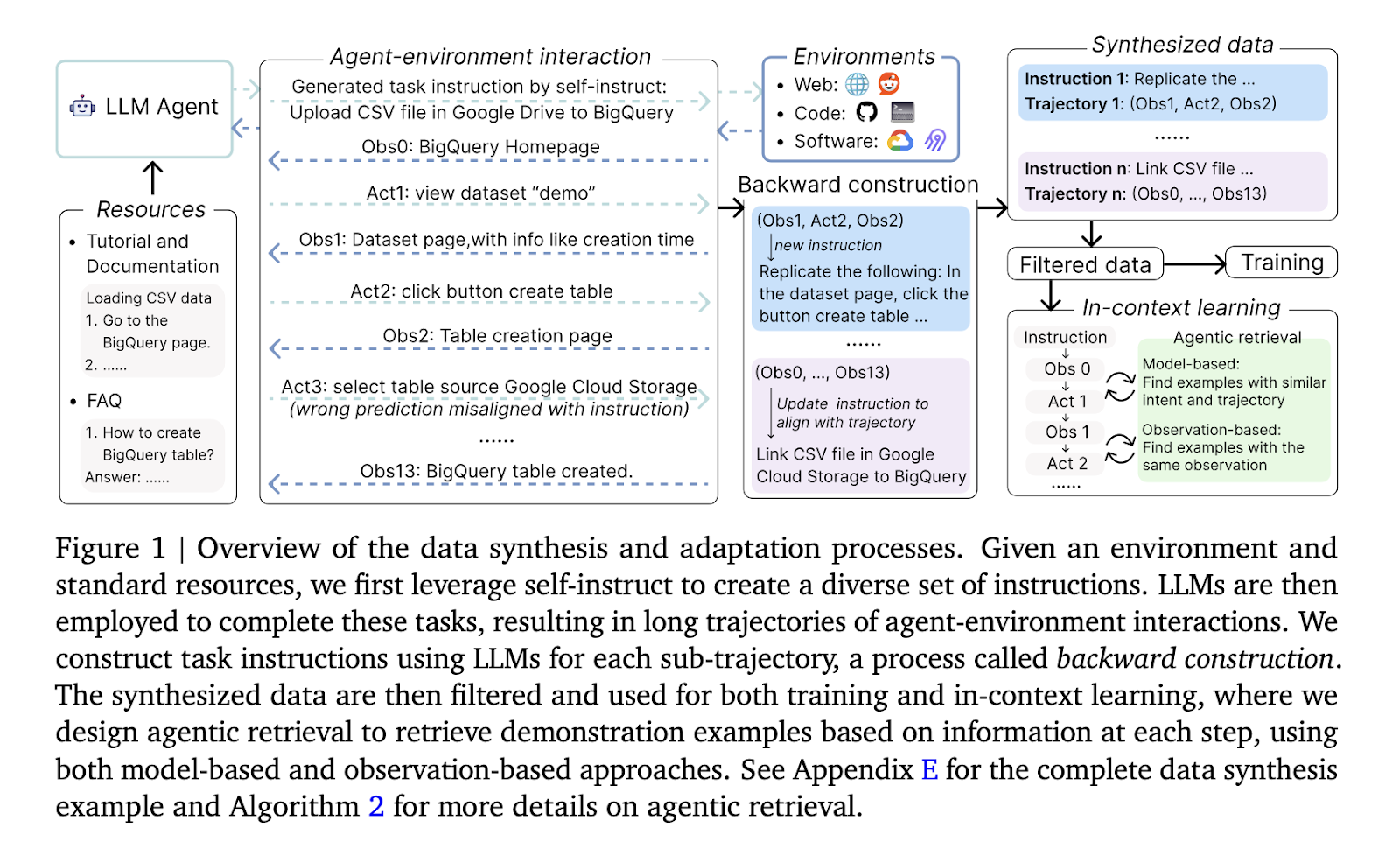
The study of autonomous agents powered by large language models (LLMs) has shown great promise in enhancing human productivity. These agents are designed to assist in various tasks such as coding, data analysis, and web navigation. They allow users to focus on creative and strategic work by automating routine digital tasks. However, despite the advancements, these systems face challenges in achieving the efficiency and reliability required for real-world applications, particularly in adapting to new environments.One of the biggest limitations in this field is a lack of quality, environment-specific datasets. Present LLMs are largely static, relying on pre-training data that do not consider dynamic and varied scenarios encountered in real-world environments. The inability to adapt has resulted in difficulties for LLMs in doing tasks that need contextual understanding or multi-step reasoning, creating a huge gap between what is potential and what these systems can do.Traditional techniques relied on human-annotated data and prompt engineering to enhance the performance of LLMs. Those generally involve retrieving instances from existing libraries or extracting information from the pre-trained models. But in doing so, they suffer from strong deficiencies like high costs, inefficiency in creating multi-round interaction datasets, and inability to scale across a vast array of domains. Other approaches, such as reinforcement learning or retrieval-augmented generation (RAG), address the gaps to some extent, but noisy data may arise, or complex trajectories fail to be adequately handled.Researchers from Google and The University of Hong Kong have presented Learn-by-Interact, a framework that addresses the abovementioned limitations. Learn-by-Interact automates interaction data synthesis by building on any accessible resource documentation, and tutorials, in this case. The framework allows agents to generate task instructions and interact within environments autonomously. These interactions are summarized and refined through backward construction, which aligns generated trajectories with task objectives. This innovation ensures that the data used for training and inference are coherent and high-quality.The methodology behind Learn-by-Interact incorporates several key processes. First, the framework uses self-instruction to create diverse task instructions from existing resources. The agents execute these instructions in simulated environments by producing interaction trajectories that are then summarized as new task instructions. Backward construction forms an integral part of this process, abstracting and realigning trajectories with their intended outcomes to ensure the alignment between the tasks and the synthesized data. Filtering mechanisms in the system filter out the noisy data, using only high-quality examples to carry forward the process. Moreover, novel retrieval pipelines further enhance the usage of synthesized data by merging observation-based and model-based methods to improve relevance and efficiency in retrieval.Thorough evaluations of Learn-by-Interact were carried out on four benchmarks: SWE-bench, WebArena, OSWorld, and Spider2-V. The framework always showed better performance than traditional methods. For instance, on OSWorld, the framework nearly doubled the baseline performance of Claude-3.5, which boosted accuracy from 12.4% to 22.5%. Codestral-22B, in training-based evaluations, showed improvement from 4.7% to 24.2% after training on data synthesized by the framework. In all benchmarks, Learn-by-Interact achieved an average improvement of 8.8% in training-free settings. These results underscore the robustness and scalability of the framework, making it an effective tool for diverse real-world applications.In addition to the good performance metrics, the study pointed out the frameworks efficiency. Unlike traditional methods that consume many computational resources, Learn-by-Interact optimizes inference by reducing the number of language model calls and tokens consumed during evaluation. The efficiency and the frameworks capability to generate high-quality data autonomously position it as a significant advancement in developing adaptive LLM agents.One of the most daunting challenges in the field is addressed by the Learn-by-Interact solution: high-quality, environment-specific synthesis at scale. It brings scalability to synthesizing such data on the back of the declining need for costly and time-consuming human annotations while achieving superior performance across different tasks. This brings considerable advancement to developing more reliable LLM agents that are practical for deployment within real-world environments. This framework introduces the use of backward construction and advanced retrieval techniques so that performance is improved and established as a new benchmark for efficiency and adaptiveness in autonomous agent research.Check out the Paper. All credit for this research goes to the researchers of this project. Also,dont forget to follow us onTwitter and join ourTelegram Channel andLinkedIn Group. Dont Forget to join our65k+ ML SubReddit. Nikhil+ postsNikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute. Meet 'Height':The only autonomous project management tool (Sponsored)
0 Σχόλια
0 Μοιράστηκε
160 Views