


Can AI Understand Subtext? A New AI Approach to Natural Language Inference
www.marktechpost.com
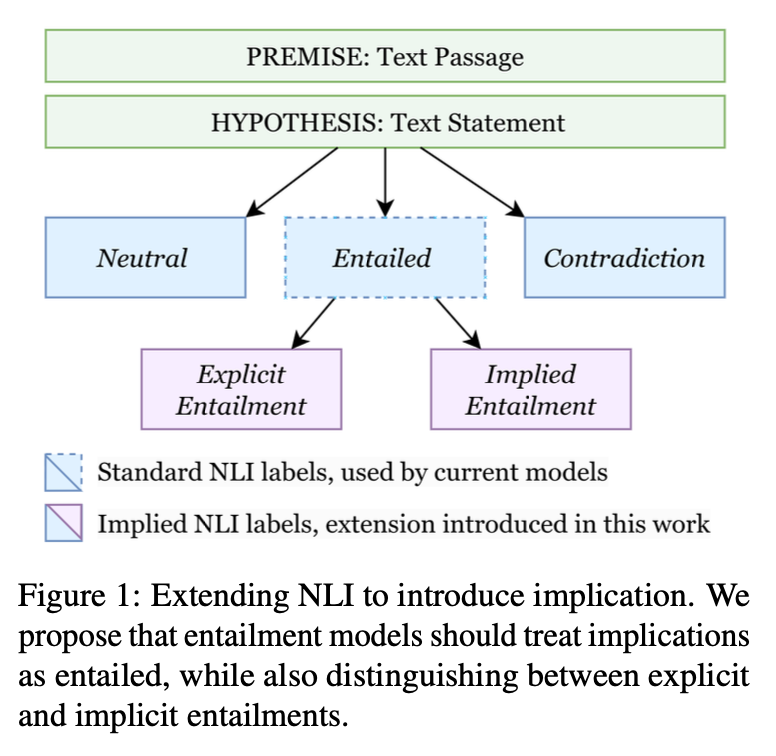
Understanding implicit meaning is a fundamental aspect of human communication. Yet, current Natural Language Inference (NLI) models struggle to recognize implied entailmentsstatements that are logically inferred but not explicitly stated. Most current NLI datasets are focused on explicit entailments, making the models insufficiently equipped to deal with scenarios where meaning is indirectly expressed. This limitation bars the development of applications such as conversational AI, summarization, and context-sensitive decision-making, where the ability to infer unspoken implications is crucial. To mitigate this shortcoming, a dataset and approach that systematically incorporates implied entailments in NLI tasks are needed.Current NLI benchmarks like SNLI, MNLI, ANLI, and WANLI are largely dominated by explicit entailments, with implied entailments making up a negligible proportion of the dataset. Therefore, state-of-the-art models trained on these datasets tend to mislabel implied entailments as neutral or contradictory. Previous efforts in introducing an understanding of implicature have been focused on structured inputs like indirect question-answering or pre-defined logical relations, which do not generalize to free-form reasoning settings. Even large models like GPT-4 exhibit a significant performance gap between explicit and implicit entailment detection, which calls for a more comprehensive approach.Google Deepmind and University of Pennsylvania researchers have proposed the Implied NLI (INLI) dataset to bridge the gap between the explicit and implicit entailments in natural language inference (NLI) models. Their paper proposes a systematic method of incorporating implied meaning in NLI training using structured implicature frameworks from current datasets such as LUDWIG, CIRCA, NORMBANK, and SOCIALCHEM to transform these frameworks into pairs of premise, implied entailment. In addition, each premise is also paired with explicit entailments, neutral hypotheses, and contradictions to create an inclusive dataset for model training. A groundbreaking few-shot prompting method using Gemini-Pro ensures the generation of high-quality implicit entailments while, concurrently, reducing annotation expenses and ensuring data integrity. Incorporating implicit meaning in NLI tasks enables the differentiation between explicit and implicit entailments by models with higher precision.The creation of the INLI dataset is a two-stage procedure. First, existing structured datasets with implicatures such as indirect replies and social norms are restructured into an implied entailment, premise format. In stage two, to ensure the strength of the dataset, explicit entailments, neutral statements, and contradictions are generated through controlled manipulation of the implied entailments. The dataset comprises 40,000 hypotheses (implied, explicit, neutral, and contradictory) for 10,000 premises, offering a diverse and balanced training set. Fine-tuning experiments using T5-XXL models employ a range of learning rates (1e-6, 5e-6, 1e-5) over 50,000 training steps to improve the identification of implicit entailments.Models fine-tuned on INLI show a dramatic improvement in detecting implied entailments, with an optimal accuracy of 92.5% compared to 5071% accuracy for models fine-tuned on typical NLI datasets. Fine-tuned models generalize well to unseen datasets with high accuracy, scoring 94.5% on NORMBANK and 80.4% on SOCIALCHEM, establishing the robustness of INLI on varied domains. Furthermore, hypothesis-only baselines prove that models fine-tuned on INLI leverage both premise and hypothesis for inference, decreasing the likelihood of shallow pattern learning. These results establish the robustness of INLI in bridging explicit and implicit entailments, and in turn, substantially improving AIs capacity for refined human communication.This paper makes significant contributions to NLI by proposing the Implied NLI (INLI) dataset, which systematically introduces implied meaning to inference tasks. Employing structured implicature frames and alternative hypothesis generation, this approach improves model accuracy for detecting implicit entailments and facilitates improved generalization across domains. With strong empirical evidence to establish its robustness, INLI establishes a new benchmark for training AI models to identify implicit meaning, leading to more nuanced and context-aware natural language understanding.Check out the Paper. All credit for this research goes to the researchers of this project. Also,dont forget to follow us onTwitter and join ourTelegram Channel andLinkedIn Group. Dont Forget to join our70k+ ML SubReddit.(Promoted) Aswin AkAswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.Aswin Akhttps://www.marktechpost.com/author/aswinak/The Allen Institute for AI (AI2) Releases Tlu 3 405B: Scaling Open-Weight Post-Training with Reinforcement Learning from Verifiable Rewards (RLVR) to Surpass DeepSeek V3 and GPT-4o in Key BenchmarksAswin Akhttps://www.marktechpost.com/author/aswinak/From Deep Knowledge Tracing to DKT2: A Leap Forward in Educational AIAswin Akhttps://www.marktechpost.com/author/aswinak/Qwen AI Introduces Qwen2.5-Max: A large MoE LLM Pretrained on Massive Data and Post-Trained with Curated SFT and RLHF RecipesAswin Akhttps://www.marktechpost.com/author/aswinak/Quantifying Knowledge Transfer: Evaluating Distillation in Large Language Models [Recommended] Join Our Telegram Channel
0 Commenti
·0 condivisioni
·42 Views