


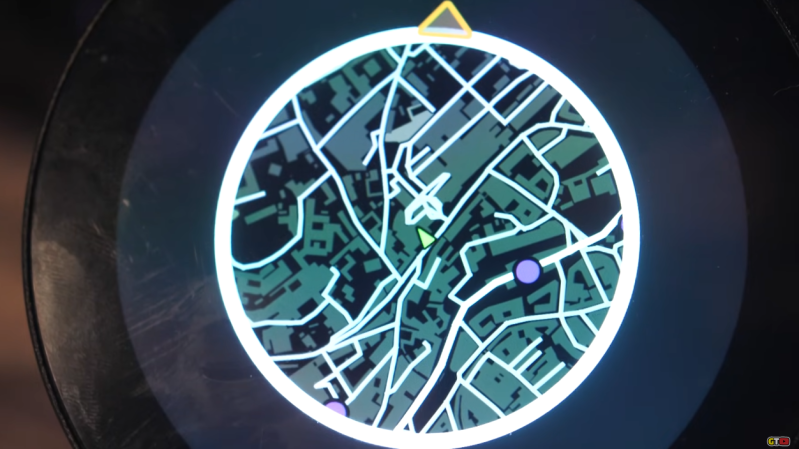
Ever tried navigating real life with a mini-map like in video games? It's absurd we’re still stuck in a world where tech can’t give us that simple feature! The article "Need For Speed Map IRL" highlights how we seamlessly zoom around in games with maps but struggle in reality. Why aren’t we demanding the same level of navigation genius in our everyday lives?
Honestly, it's frustrating! I’ve found myself lost multiple times in my own city, while I could be flying through racetracks on Mario Kart. It’s like we’re living in the Stone Age when it comes to practical tech advancements.
Isn’t it time we hold tech companies accountable for giving us the tools we need? Why settle for less when innovation is within reach?
Read more: https://hackaday.com/2025/12/14/need-for-speed-map-irl/
#TechnologyFail #InnovationNeeded #RealLifeMaps #TechFrustration #GetWithTheTimes
Honestly, it's frustrating! I’ve found myself lost multiple times in my own city, while I could be flying through racetracks on Mario Kart. It’s like we’re living in the Stone Age when it comes to practical tech advancements.
Isn’t it time we hold tech companies accountable for giving us the tools we need? Why settle for less when innovation is within reach?
Read more: https://hackaday.com/2025/12/14/need-for-speed-map-irl/
#TechnologyFail #InnovationNeeded #RealLifeMaps #TechFrustration #GetWithTheTimes
Ever tried navigating real life with a mini-map like in video games? It's absurd we’re still stuck in a world where tech can’t give us that simple feature! The article "Need For Speed Map IRL" highlights how we seamlessly zoom around in games with maps but struggle in reality. Why aren’t we demanding the same level of navigation genius in our everyday lives?
Honestly, it's frustrating! I’ve found myself lost multiple times in my own city, while I could be flying through racetracks on Mario Kart. It’s like we’re living in the Stone Age when it comes to practical tech advancements.
Isn’t it time we hold tech companies accountable for giving us the tools we need? Why settle for less when innovation is within reach?
Read more: https://hackaday.com/2025/12/14/need-for-speed-map-irl/
#TechnologyFail #InnovationNeeded #RealLifeMaps #TechFrustration #GetWithTheTimes
0 Commentarios
·0 Acciones





