www.computerweekly.com
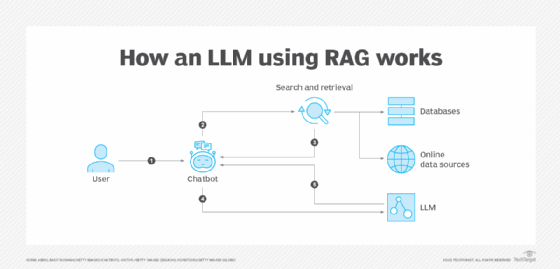
All the large language model (LLM) publishers and suppliers are focusing on the advent of artificial intelligence (AI) agents and agentic AI. These terms are confusing. All the more so as the players do not yet agree on how to develop and deploy them.This is much less true for retrieval augmented generation (RAG) architectures where, since 2023, there has been widespread consensus in the IT industry.Augmented generation through retrieval enables the results of a generative AI model to be anchored in truth. While it does not prevent hallucinations, the method aims to obtain relevant answers, based on a company's internal data or on information from a verified knowledge base.It could be summed up as the intersection of generative AI and an enterprise search engine.Broadly speaking, the process of a RAG system is simple to understand. It starts with the user sending a prompt - a question or request. This natural language prompt and the associated query are compared with the content of the knowledge base. The results closest to the request are ranked in order of relevance, and the whole process is then sent to an LLM to produce the response sent back to the user.The companies that have tried to deploy RAG have learned the specifics of such an approach, starting with support for the various components that make up the RAG mechanism. These components are associated with the steps required to transform the data, from ingesting it into a source system to generating a response using an LLM.The first step is to gather the documents you want to search. While it is tempting to ingest all the documents available, this is the wrong strategy. Especially as you have to decide whether to update the system in batch or continuously."Failures come from the quality of the input. Some customers say to me: 'I've got two million documents, you've got three weeks, give me a RAG'. Obviously, it doesn't work," says Bruno Maillot, director of the AI for Business practice at Sopra Steria Next. "This notion of refinement is often forgotten, even though it was well understood in the context of machine learning. Generative AI doesn't make Chocapic".An LLM is not de facto a data preparation tool. It is advisable to remove duplicates and intermediate versions of documents and to apply strategies for selecting up-to-date items. This pre-selection avoids overloading the system with potentially useless information and avoids performance problems.Once the documents have been selected, the raw data - HTML pages, PDF documents, images, doc files, etc - needs to be converted into a usable format, such astext and associated metadata, expressed in a JSON file, for example. This metadata can not only document the structure of the data, but also its authors, origin, date of creation, and so on. This formatted data is then transformed into tokens and vectors.Publishers quickly realised that with large volumes of documents and long texts, it was inefficient to vectorise the whole document.Hence the importance of implementing a "chunking" strategy. This involves breaking down a document into short extracts. A crucial step, according to Mistral AI, which says, "It makes it easier to identify and retrieve the most relevant information during the search process".There are two considerations here - the size of the fragments and the way in which they are obtained.The size of a chunk is often expressed as a number of characters or tokens. A larger number of chunks improves the accuracy of the results, but the multiplication of vectors increases the amount of resources and time required to process them.There are several ways of dividing a text into chunks.The first is to slice according to fragments of fixed size - characters, words or tokens. "This method is simple, which makes it a popular choice for the initial phases of data processing where you need to browse the data quickly," says Ziliz, a vector database editor.A second approach consists of a semantic breakdown that is, based on a "natural" breakdown: by sentence, by section - defined by an HTML header for example - subject or paragraph. Although more complex to implement, this method is more precise. It often depends on a recursive approach, since it involves using logical separators, such as a space, comma, full stop, heading, and so on.The third approach is a combination of the previous two. Hybrid chunking combines an initial fixed breakdown with a semantic method when a very precise response is required.In addition to these techniques, it is possible to chain the fragments together, taking into account that some of the content of the chunks may overlap."Overlap ensures that there is always some margin between segments, which increases the chances of capturing important information even if it is split according to the initial chunking strategy," according to documentation from LLM platform Cohere. "The disadvantage of this method is that it generates redundancy.The most popular solution seems to be to keep fixed fragments of 100 to 200 words with an overlap of 20% to 25% of the content between chunks.This splitting is often done using Python libraries, such as SpaCy or NTLK, or with the text splitters tools in the LangChain framework.The right approach generally depends on the precision required by users. For example, a semantic breakdown seems more appropriate when the aim is to find specific information, such as the article of a legal text.The size of the chunks must match the capacities of the embedding model. This is precisely why chunking is necessary in the first place. This "allows you to stay below the input token limit of the embedding model", explains Microsoft in its documentation. "For example, the maximum length of input text for the Azure OpenAI text-embedding-ada-002 model is 8,191 tokens. Given that one token corresponds on average to around four characters with current OpenAI models, this maximum limit is equivalent to around 6,000 words".An embedding model is responsible for converting chunks or documents into vectors. These vectors are stored in a database.Here again, there are several types of embedding model, mainly dense and sparse models. Dense models generally produce vectors of fixed size, expressed in x number of dimensions. The latter generate vectors whose size depends on the length of the input text. A third approach combines the two to vectorise short extracts or comments (Splade, ColBERT, IBM sparse-embedding-30M).The choice of the number of dimensions will determine the accuracy and speed of the results. A vector with many dimensions captures more context and nuance, but may require more resources to create and retrieve. A vector with fewer dimensions will be less rich, but faster to search.The choice of embedding model also depends on the database in which the vectors will be stored, the large language model with which it will be associated and the task to be performed. Benchmarks such as the MTEB ranking are invaluable. It is sometimes possible to use an embedding model that does not come from the same LLM collection, but it is necessary to use the same embedding model to vectorise the document base and user questions.Note that it is sometimes useful to fine-tune the embeddings model when it does not contain sufficient knowledge of the language related to a specific domain, for example, oncology or systems engineering.Vector databases do more than simply store vectors - they generally incorporate a semantic search algorithm based on the nearest-neighbour technique to index and retrieve information that corresponds to the question. Most publishers have implemented the Hierarchical Navigable Small Worlds (HNSW) algorithm. Microsoft is also influential with DiskANN, an open source algorithm designed to obtain an ideal performance-cost ratio with large volumes of vectors, at the expense of accuracy. Google has chosen to develop a proprietary model, ScANN, also designed for large volumes of data. The search process involves traversing the dimensions of the vector graph in search of the nearest approximate neighbour, and is based on a cosine or Euclidean distance calculation.The cosine distance is more effective at identifying semantic similarity, while the Euclidean method is simpler, but less demanding in terms of computing resources.Since most databases are based on an approximate search for nearest neighbours, the system will return several vectors potentially corresponding to the answer. It is possible to limit the number of results (top-k cutoff). This is even necessary, since we want the user's query and the information used to create the answer to fit within the LLM context window. However, if the database contains a large number of vectors, precision may suffer or the result we are looking for may be beyond the limit imposed.Combining a traditional search model such as BM25 with an HNSW-type retriever can be useful for obtaining a good cost-performance ratio, but it will also be limited to a restricted number of results. All the more so as not all vector databases support the combination of HNSW models with BM25 (also known as hybrid search).A reranking model can help to find more content deemed useful for the response. This involves increasing the limit of results returned by the "retriever" model. Then, as its name suggests, the reranker reorders the chunks according to their relevance to the question. Examples of rerankers include Cohere Rerank, BGE, Janus AI and Elastic Rerank. On the other hand, such a system can increase the latency of the results returned to the user. It may also be necessary to re-train this model if the vocabulary used in the document base is specific. However, some consider it useful - relevance scores are useful data for supervising the performance of a RAG system.Reranker or not, it is necessary to send the responses to the LLMs. Here again, not all LLMs are created equal - the size of their context window, their response speed and their ability to respond factually (even without having access to documents) are all criteria that need to be evaluated. In this respect, Google DeepMind, OpenAI, Mistral AI, Meta and Anthropic have trained their LLMs to support this use case.In addition to the reranker, an LLM can be used as a judge to evaluate the results and identify potential problems with the LLM that is supposed to generate the response. Some APIs rely instead on rules to block harmful content or requests for access to confidential documents for certain users. Opinion-gathering frameworks can also be used to refine the RAG architecture. In this case, users are invited to rate the results in order to identify the positive and negative points of the RAG system. Finally, observability of each of the building blocks is necessary to avoid problems of cost, security and performance.Read more about AI, LLMs and RAGWhy run AI on-premise? Much of artificial intelligences rapid growth has come from cloud-based tools. But there are very good reasons to host AI workloads on-premiseAdvancing LLM precision & reliability - This is a guest post written by Ryan Mangan, datacentre and cloud evangelist and founder of Efficient Ether.Why responsible AI is a business imperative - Tools are emerging for real-world AI systems that focus more on responsible adoption, deployment and governance, rather than academic and philosophical questions about speculative risks.