Meet CoMERA: An Advanced Tensor Compression Framework Redefining AI Model Training with Speed and Precision
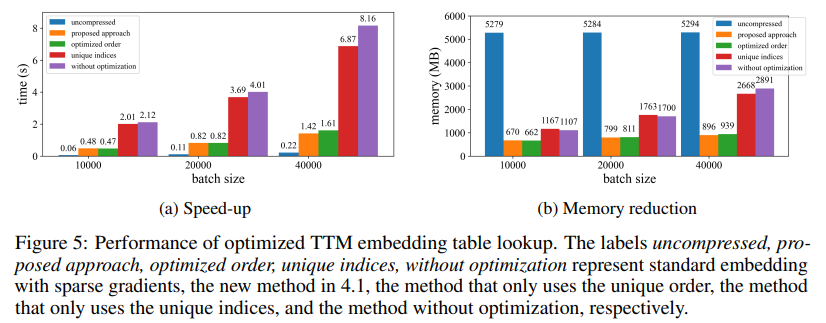
Training large-scale AI models such as transformers and language models have become an indispensable yet highly demanding process in AI. With billions of parameters, these models offer groundbreaking capabilities but come at a steep cost in terms of computational power, memory, and energy consumption. For example, OpenAIs GPT-3 comprises 175 billion parameters and requires weeks of GPU training. Such massive requirements limit these technologies to organizations with substantial computational resources, exacerbating concerns over energy efficiency and environmental impact. Addressing these challenges has become critical to ensuring the broader accessibility and sustainability of AI advancements.The inefficiencies in training large models stem primarily from their reliance on dense matrices, which demand significant memory and computing power. The limited support for optimized low-precision or low-rank operations in modern GPUs further compounds these requirements. While some methods, such as matrix factorization and heuristic rank reduction, have been proposed to alleviate these issues, their real-world applicability is constrained. For instance, GaLore enables training on single-batch settings but suffers from impractical runtime overhead. Similarly, LTE, which adopts low-rank adapters, struggles with convergence on large-scale tasks. The lack of a method that simultaneously reduces memory usage, computational cost, and training time without compromising performance has created an urgent need for innovative solutions.Researchers from the University at Albany SUNY, the University of California at Santa Barbara, Amazon Alexa AI, and Meta introduced Computing-and Memory-Efficient training method via Rank-Adaptive tensor optimization (CoMERA), a novel framework that combines memory efficiency with computational speed through rank-adaptive tensor compression. Unlike traditional methods focusing solely on compression, CoMERA adopts a multi-objective optimization approach to balance compression ratio and model accuracy. It utilizes tensorized embeddings and advanced tensor-network contractions to optimize GPU utilization, reducing runtime overhead while maintaining robust performance. The framework also introduces CUDA Graph to minimize kernel-launching delays during GPU operations, a significant bottleneck in traditional tensor compression approaches.CoMERAs foundation is based on adaptive tensor representations, which allow model layers to adjust their ranks dynamically based on resource constraints. By modifying tensor ranks, the framework achieves compression without compromising the integrity of neural network operations. This dynamic optimization is achieved through a two-stage training process:An early stage focused on stable convergenceA late stage that fine-tunes ranks to meet specific compression targetsIn a six-encoder transformer model, CoMERA achieved compression ratios ranging from 43x in its early stage to an impressive 361x in its late-stage optimizations. Also, it reduced memory consumption by 9x compared to GaLore, with 2-3x faster training per epoch.When applied to transformer models trained on the MNLI dataset, CoMERA reduced model sizes from 256 MB to as little as 3.2 MB while preserving accuracy. In large-scale recommendation systems like DLRM, CoMERA compressed models by 99x and achieved a 7x reduction in peak memory usage. The framework also excelled in pre-training CodeBERT, a domain-specific large language model, where it gained a 4.23x overall compression ratio and demonstrated a 2x speedup during certain training phases. These results underscore its ability to handle diverse tasks and architectures, extending its applicability across domains.The key takeaways from this research are as follows:CoMERA achieved compression ratios of up to 361x for specific layers and 99x for full models, drastically reducing storage and memory requirements.The framework delivered 2-3x faster training times per epoch for transformers and recommendation systems, saving computational resources and time.Using tensorized representations and CUDA Graph, CoMERA reduced peak memory consumption by 7x, enabling training on smaller GPUs.CoMERAs approach supports diverse architectures, including transformers and large language models, while maintaining or improving accuracy.By lowering the energy and resource demands of training, CoMERA contributes to more sustainable AI practices and makes cutting-edge models accessible to a broader audience.In conclusion, CoMERA addresses some of the most significant barriers to AI scalability and accessibility by enabling faster, memory-efficient training. Its adaptive optimization capabilities and compatibility with modern hardware make it a compelling choice for organizations seeking to train large models without incurring prohibitive costs. This studys results pave the way for further exploration of tensor-based optimizations in domains like distributed computing and resource-constrained edge devices.Check out the Paper. All credit for this research goes to the researchers of this project. Also,dont forget to follow us onTwitter and join ourTelegram Channel andLinkedIn Group. Dont Forget to join our60k+ ML SubReddit. Asif RazzaqAsif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [Download] Evaluation of Large Language Model Vulnerabilities Report (Promoted)