www.marktechpost.com
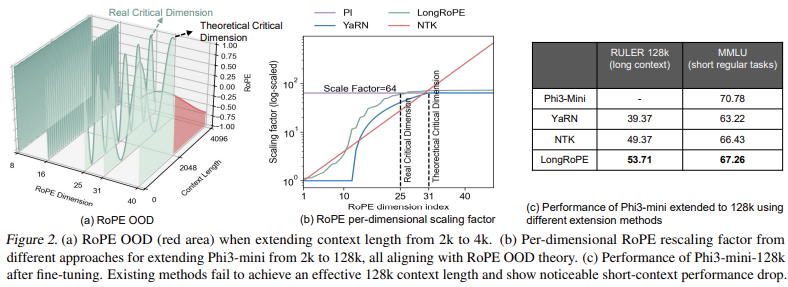
Large Language Models (LLMs) have advanced significantly, but a key limitation remains their inability to process long-context sequences effectively. While models like GPT-4o and LLaMA3.1 support context windows up to 128K tokens, maintaining high performance at extended lengths is challenging. Rotary Positional Embeddings (RoPE) encode positional information in LLMs but suffer from out-of-distribution (OOD) issues when applied beyond their pre-trained limits. These OOD values appear in higher-dimensional RoPE embeddings, leading to degraded performance. Longer context windows are essential for AI applications such as multi-turn conversations, document analysis, and long-form reasoning. LLMs struggle with efficiency and accuracy when scaling beyond their default lengths without an effective extension method.Most existing methods for extending context windows rely on heuristic-based RoPE rescaling, which fails to address OOD issues fully and often falls short of the target effective context length. Approaches like YaRN, NTK, and LongRoPE derive rescaling factors from theoretical models, but real-world testing reveals significant performance trade-offs. For example, when LLaMA3.1 extends its context window using YaRN, performance drops sharply beyond 64K tokens, as shown in the RULER benchmark. Extending context length also frequently reduces short-context performance, making these methods impractical for short- and long-range processing applications. This issue is particularly severe in models like Phi3-mini-3.8B, where naive RoPE extensions reduce MMLU scores by 7.56 points.Researchers from Microsoft have introduced LongRoPE2 to overcome these limitations. LongRoPE2 is designed to extend the context window of LLMs to 128K tokens while preserving over 98.5% of short-context accuracy. It achieves this by addressing three core issues. First, the research team hypothesized that higher RoPE dimensions receive insufficient training, leading to unexpected OOD values when extending token positions. To mitigate this, LongRoPE2 introduces a needle-driven perplexity (PPL) evaluation that specifically targets tokens that require deep contextual understanding, unlike traditional perplexity measures that fail to distinguish between essential and non-essential tokens. Second, LongRoPE2 adopts an evolutionary search-based RoPE rescaling algorithm, which optimizes rescaling factors beyond theoretical assumptions, ensuring better alignment with extended contexts. Finally, it incorporates mixed context window training, in which the model is fine-tuned on both short and long sequences, thereby preventing performance loss on short-context tasks while ensuring effective long-context adaptation.The technical approach of LongRoPE2 begins with identifying the true critical dimension in RoPE embeddings. The study found that theoretical critical dimensions underestimate the true RoPE scaling needs, as evidenced by empirical observations where RoPE dimensions required larger-than-predicted scaling factors for optimal performance. This led to the development of an adaptive rescaling method that fine-tunes RoPE scaling factors using an iterative evolutionary search. Unlike previous static scaling methods, LongRoPE2 dynamically adjusts rescaling based on per-token perplexity evaluations, ensuring embeddings remain within the pre-trained range while maximizing their effectiveness in long contexts. The algorithm identifies the optimal rescaling factors for higher RoPE dimensions while applying NTK scaling to lower dimensions, ensuring a smooth adaptation process. This method effectively extends LLaMA3-8B to 128K tokens, maintaining over 97% of its short-context accuracy while outperforming prior methods on long-context benchmarks.Performance evaluations reveal LongRoPE2s superiority across various benchmarks. Extensive Phi3-mini-3.8B and LLaMA3-8B testing shows that LongRoPE2 achieves state-of-the-art RULER, LongBench, and InfiniteBench results. On the RULER benchmark, which evaluates LLMs long-context processing capabilities, LongRoPE2 extended LLaMA3-8B to 128K tokens while retaining a score of 82.03, compared to 73.40 for LongRoPE and 49.39 for YaRN. Phi3-mini-3.8B exhibited even greater improvements, with a 128K token score of 58.81, significantly outperforming NTK, which only achieved 49.37 at the same context length. One of the most striking findings was that Metas approach required 800B training tokens to reach 128K tokens, whereas LongRoPE2 accomplished this using only 10B tokens, an 80x efficiency gain. In addition, LongRoPE2 achieved near-perfect accuracy in the Needle in a Haystack pressure test, demonstrating its ability to retrieve deeply embedded information in long sequences, where previous methods such as NTK often failed at extended lengths.One of the key takeaways from this research is that extending LLM context windows is not just a matter of increasing token length but requires addressing fundamental limitations in positional embeddings. The findings suggest that higher RoPE dimensions are insufficiently trained, necessitating adaptive scaling rather than fixed rescaling factors. The needle-driven PPL evaluation proved crucial in identifying the optimal RoPE scaling factors, ensuring that models maintain accuracy in long-range dependencies. The mixed context window training technique ensured that models retained over 97.6% of their short-context performance, making LongRoPE2 the first near-lossless extension method. Also, LongRoPE2s evolutionary search for RoPE rescaling factors revealed that prior analytical methods underestimated scaling needs in high-dimensional embeddings, leading to suboptimal performance in previous approaches.Some Key Highlights from the Research include:LongRoPE2 successfully extended LLaMA3-8B to 128K tokens with 82.03% accuracy, surpassing all previous methods.Unlike Metas approach, which required 800B training tokens, LongRoPE2 achieved the same extension using only 10B tokens, making it 80x more efficient.The model retained 97.6% of short-context performance, whereas prior methods degraded significantly.The needle-driven perplexity evaluation introduced a novel method for determining optimal RoPE rescaling factors, allowing precise adaptation to long contexts.On the RULER benchmark, LongRoPE2 scored 82.03 at 128K, compared to 73.40 for LongRoPE and 49.39 for YaRN.The model achieved near-perfect retrieval accuracy in the Needle in a Haystack test, significantly outperforming NTK-based approaches.LongRoPE2 demonstrated that adaptive evolutionary search-based scaling is far superior to static rescaling techniques.Check outthe Paper and GitHub Page.All credit for this research goes to the researchers of this project. Also,feel free to follow us onTwitterand dont forget to join our80k+ ML SubReddit. Asif RazzaqWebsite| + postsBioAsif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.Asif Razzaqhttps://www.marktechpost.com/author/6flvq/IBM AI Releases Granite 3.2 8B Instruct and Granite 3.2 2B Instruct Models: Offering Experimental Chain-of-Thought Reasoning CapabilitiesAsif Razzaqhttps://www.marktechpost.com/author/6flvq/Google AI Introduces PlanGEN: A Multi-Agent AI Framework Designed to Enhance Planning and Reasoning in LLMs through Constraint-Guided Iterative Verification and Adaptive Algorithm SelectionAsif Razzaqhttps://www.marktechpost.com/author/6flvq/DeepSeek AI Releases Fire-Flyer File System (3FS): A High-Performance Distributed File System Designed to Address the Challenges of AI Training and Inference WorkloadAsif Razzaqhttps://www.marktechpost.com/author/6flvq/Cohere AI Releases Command R7B Arabic: A Compact Open-Weights AI Model Optimized to Deliver State-of-the-Art Arabic Language Capabilities to Enterprises in the MENA Region Recommended Open-Source AI Platform: IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System' (Promoted)