


How to read LLM benchmarks
uxdesign.cc
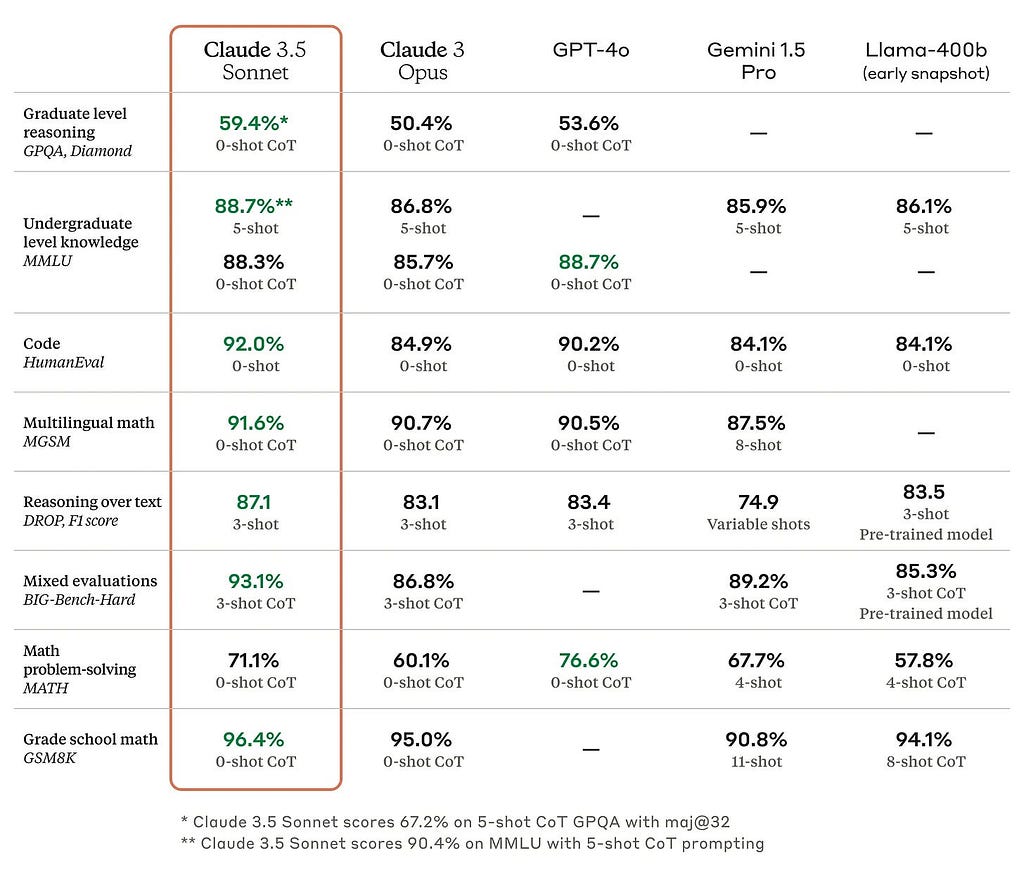
And why you shouldnt trust themblindlySource: Anthropics Claude 3.5 Sonnet blogpostDisclaimer: The opinions stated here are my own, not necessarily those of my employer.Every once in a while, theres an announcement about a new model. Its always better than its predecessor and its also better than all of the other frontier models in the market. The announcement comes with a table that looks likethis:The high-level message delivered here is we are better than everyone else at almost everything.But how exactly is this claim made? What do these numbers mean? Can you take them at face value? Lets break itdown.Why BenchmarksImagine youre selling a car and you want to claim that its the best car on the market. However, potential buyers look for different featuressome want the safest car, while others want the fastest. To convince the broadest audience to choose your car, you compare it against competitors using universally understood data: Safety rating, Fuel efficiency, 0-to-60 time,etc.LLM Benchmarks serve a similar purpose. They are standardized tests and datasets designed to evaluate the performance of models across various tasks. They provide metrics and criteria to compare different models, ensuring consistency and objectivity in assessments.How Benchmarks WorkEach Benchmark evaluates a capability that the LLM might be used for. HumanEval, for example, tests the models ability to write code. It consists of a set of 164 programming challenges (ex: finding a substring within a large string) and uses unit tests to check the functional correctness of generated code.Another example is Reasoning, which can be defined in different ways. For the purposes of benchmarking, its defined as the ability to answer hard, complex questions that require step-by-step deduction and analyzing data. Heres an example: Two quantum states with energies E1 and E2 have a lifetime of 10^-9 sec and 10^-8 sec, respectively. We want to clearly distinguish these two energy levels. Which one of the following options could be their energy difference so that they be clearly resolved? This question will sound hard unless youre a physicist (or if you enjoy devouring books about quantum mechanics for some reason). It was from the GPQA benchmark, which has 448 such questions across different fields. Models receive a score based on how many questions they answer correctly.Other tests include Language understanding (MMLU) and Math problem solving (MATH). They are similar tests with other types of questions. But within each test, its the same set of questions that every model is evaluated against. This is how consistency is maintained (not unlike the idea of humans taking standardized tests).CoT &Few-shotZooming into the same ClaudetableFew-shot (like 3-shot) refers to the amount of examples that were given to the model to better understand the task. 0-shot means no examples were given. CoT refers to Chain-of-Thought, where the model is asked to explain its reasoning process. CoT and examples can help improve response quality for certain tasks, which is why they are separately highlighted in benchmark results. Heres an example I got from ChatGPT to explainCoT:The problem with these BenchmarksLack of transparencyWe dont know how a model was trained. We dont know how the benchmark tests were run. Then how can we say for sure that the model was not trained on the testing data? This issue is called contamination, which is a common problem in Machine Learning.The sheer amount of data that LLMs are trained on has made it impossibly hard to detect or avoid this problem. Its the human equivalent of finding out all the questions before the day of theexam.Do these exams really measure ability or intelligence?Its likely that a significant portion of benchmark results can be explained by the ability of LLMs to memorize vast amounts of data. Then, are they really more capable than humans just because they got a better score? Heres another exampleThere was news last year of ChatGPT acing the LSAT. Its a pretty impressive feat, except when you think about (a) The fact that the LSAT usually contains questions from previous years and (b) How LSAT questions from previous years are freely available all over the internet. If ChatGPT aced the LSAT after seeing the questions before the test, would you still replace your lawyer withit?How to choose foryourselfIf youre a developer or a team trying to use AI in your product, you need to construct your own evaluation. This evaluation needs to be focused on the use cases that matter to you. The dataset needs to be customized based on your requirements.An exampleIf you want to automate customer service for your business, build a dataset of questions that your customers might ask. Then, build a system to prompt any LLM with these questions and score the answers they give you. Run this activity between the models you are considering and then make yourchoice.If youre an individual user looking to decide if you need to switch between Claude and ChatGPT, you can build a set of your most commonly used prompts (write a cover letter, generate an image of, etc) and compare the different responses before making your decision. Even if the results arent statistically significant (unless you ask a lot of questions and repeat this process multiple times), its a controllable system that can explain your decision making. IMO, its much better than opaque benchmarking processes run by companies that are selling models toyou.Further reading on running evaluations can be found here. Better writing on the problems with benchmarks can be found here andhere.Disclaimer: The opinions stated here are my own, not necessarily those of my employer.Please consider subscribing to my substack if you liked this article. Thankyou!How to read LLM benchmarks was originally published in UX Collective on Medium, where people are continuing the conversation by highlighting and responding to this story.
0 Comentários
·0 Compartilhamentos
·144 Visualizações