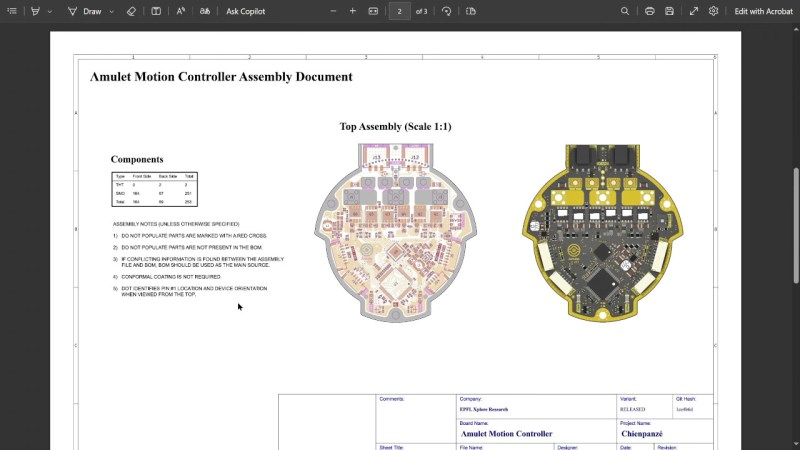
Ever wondered what happens when your Sub-D base mesh is TOO low? Dive into our latest Blender tutorial and unlock the secrets to perfecting your 3D models!
In this snippet from the Collabs Course, you’ll learn crucial tips to elevate your Blender skills while we document the making of our animated short, "Peacemaker Protocol." Whether you're a beginner or a seasoned pro, this video is packed with insights you won't want to miss!
We’re all about sharing knowledge and resources with the Blender community. Join us on this creative journey—your next masterpiece is just a click away!
Watch the full video here:
https://www.youtube.com/watch?v=jMTnfTIwyLA
#CGCookie #Blendertutorial #3DModeling #BlenderArtists #PeacemakerProtocol
In this snippet from the Collabs Course, you’ll learn crucial tips to elevate your Blender skills while we document the making of our animated short, "Peacemaker Protocol." Whether you're a beginner or a seasoned pro, this video is packed with insights you won't want to miss!
We’re all about sharing knowledge and resources with the Blender community. Join us on this creative journey—your next masterpiece is just a click away!
Watch the full video here:
https://www.youtube.com/watch?v=jMTnfTIwyLA
#CGCookie #Blendertutorial #3DModeling #BlenderArtists #PeacemakerProtocol
Ever wondered what happens when your Sub-D base mesh is TOO low? 🤔 Dive into our latest Blender tutorial and unlock the secrets to perfecting your 3D models! 🌟
In this snippet from the Collabs Course, you’ll learn crucial tips to elevate your Blender skills while we document the making of our animated short, "Peacemaker Protocol." Whether you're a beginner or a seasoned pro, this video is packed with insights you won't want to miss!
We’re all about sharing knowledge and resources with the Blender community. Join us on this creative journey—your next masterpiece is just a click away!
Watch the full video here:
https://www.youtube.com/watch?v=jMTnfTIwyLA
#CGCookie #Blendertutorial #3DModeling #BlenderArtists #PeacemakerProtocol

0 Comments
·0 Shares