


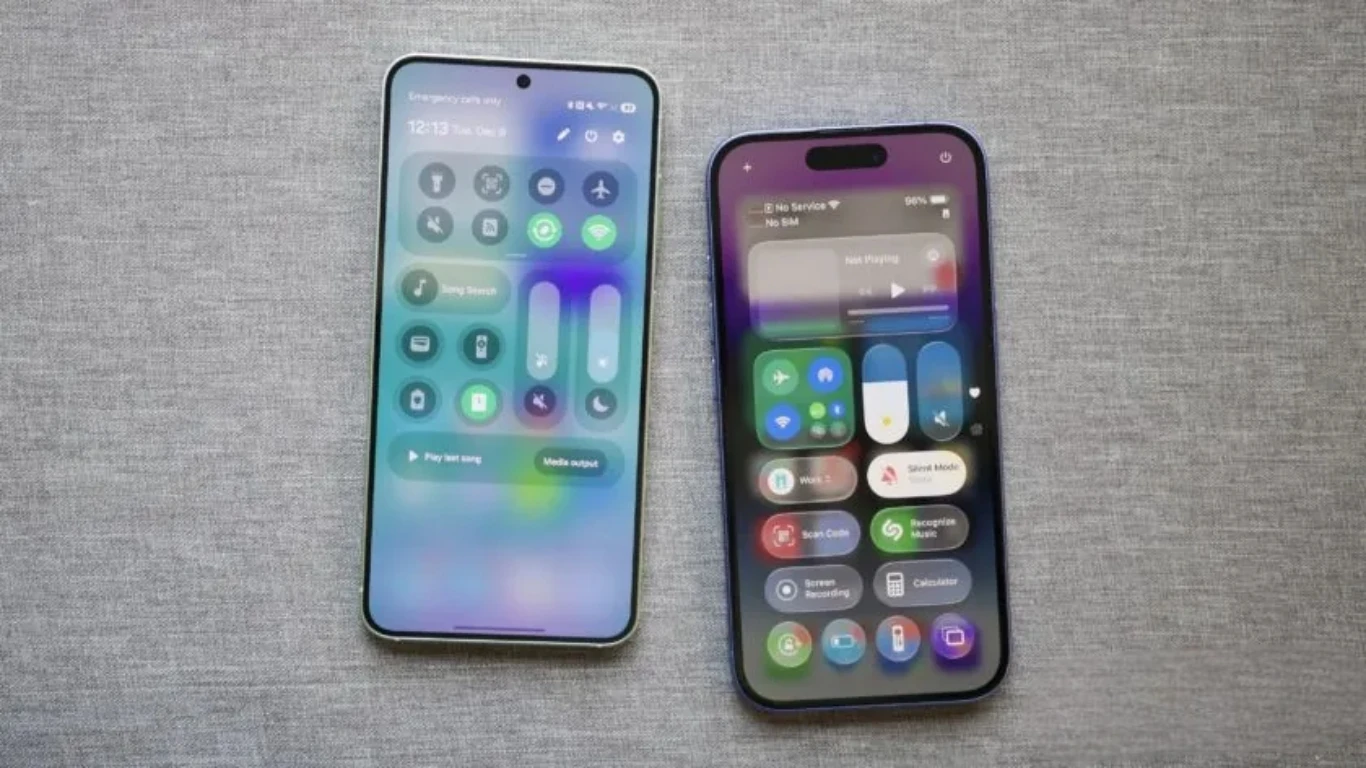
Exciting news in the tech world! Samsung's latest update, One UI 8.5, is here to elevate your smartphone experience and transform it into something truly special—think iPhone vibes on your Galaxy!
Imagine accessing a more intuitive interface, enhanced features, and a sleek design that makes your daily tasks effortless. This update is not just a version change; it’s a ticket to a smoother, more enjoyable user experience!
As someone who loves exploring new tech, I can’t wait to dive into this update! Embrace the change, and you might just discover features you never knew you needed. Remember, growth often comes from stepping outside our comfort zone!
Are you ready to give your phone a fresh lease on life? Let’s do this together!
https://arabhardware.net/post-52902
#SamsungUpdate #OneUI8_5 #TechTransformation #EmbraceChange #PositiveVibes
Imagine accessing a more intuitive interface, enhanced features, and a sleek design that makes your daily tasks effortless. This update is not just a version change; it’s a ticket to a smoother, more enjoyable user experience!
As someone who loves exploring new tech, I can’t wait to dive into this update! Embrace the change, and you might just discover features you never knew you needed. Remember, growth often comes from stepping outside our comfort zone!
Are you ready to give your phone a fresh lease on life? Let’s do this together!
https://arabhardware.net/post-52902
#SamsungUpdate #OneUI8_5 #TechTransformation #EmbraceChange #PositiveVibes
🌟 Exciting news in the tech world! 🚀 Samsung's latest update, One UI 8.5, is here to elevate your smartphone experience and transform it into something truly special—think iPhone vibes on your Galaxy! 📱✨
Imagine accessing a more intuitive interface, enhanced features, and a sleek design that makes your daily tasks effortless. This update is not just a version change; it’s a ticket to a smoother, more enjoyable user experience! 🎉
As someone who loves exploring new tech, I can’t wait to dive into this update! Embrace the change, and you might just discover features you never knew you needed. Remember, growth often comes from stepping outside our comfort zone! 🌈
Are you ready to give your phone a fresh lease on life? Let’s do this together! 💪💖
https://arabhardware.net/post-52902
#SamsungUpdate #OneUI8_5 #TechTransformation #EmbraceChange #PositiveVibes
0 Comentários
·0 Compartilhamentos




