NVIDIA and Microsoft Advance Development on RTX AI PCs
Generative AI is transforming PC software into breakthrough experiences — from digital humans to writing assistants, intelligent agents and creative tools.
NVIDIA RTX AI PCs are powering this transformation with technology that makes it simpler to get started experimenting with generative AI and unlock greater performance on Windows 11.
NVIDIA TensorRT has been reimagined for RTX AI PCs, combining industry-leading TensorRT performance with just-in-time, on-device engine building and an 8x smaller package size for seamless AI deployment to more than 100 million RTX AI PCs.
Announced at Microsoft Build, TensorRT for RTX is natively supported by Windows ML — a new inference stack that provides app developers with both broad hardware compatibility and state-of-the-art performance.
For developers looking for AI features ready to integrate, NVIDIA software development kitsoffer a wide array of options, from NVIDIA DLSS to multimedia enhancements like NVIDIA RTX Video. This month, top software applications from Autodesk, Bilibili, Chaos, LM Studio and Topaz Labs are releasing updates to unlock RTX AI features and acceleration.
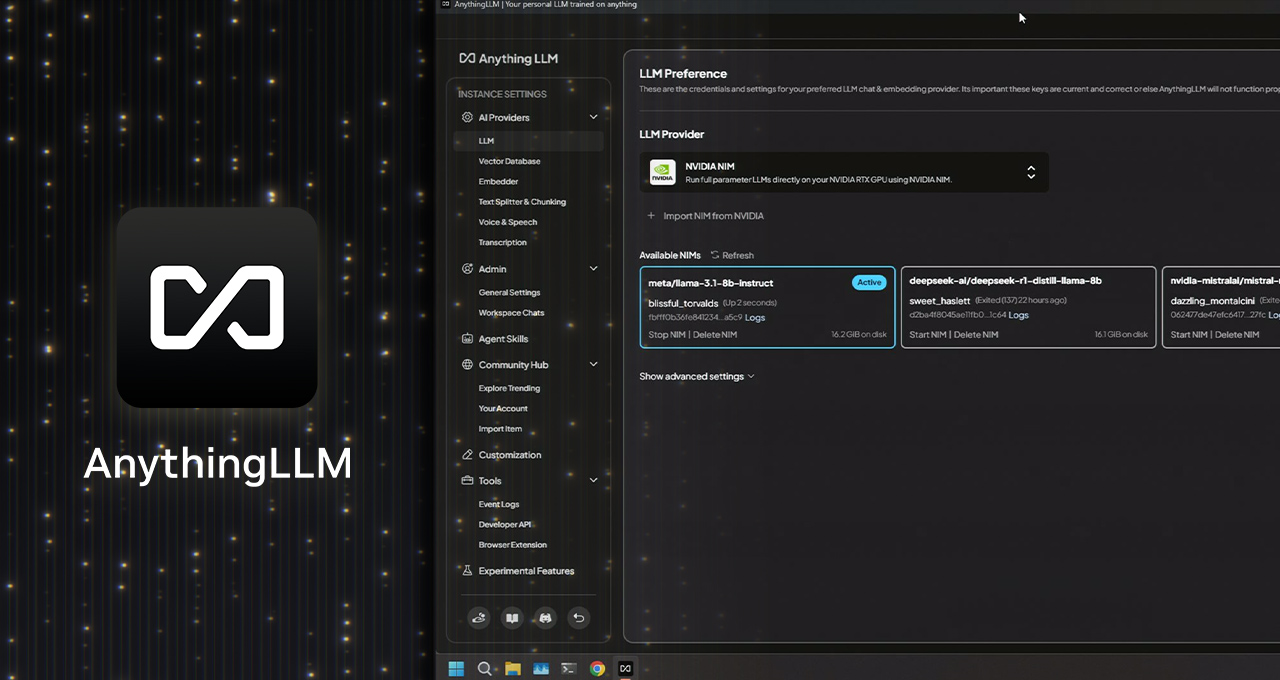
AI enthusiasts and developers can easily get started with AI using NVIDIA NIM — prepackaged, optimized AI models that can run in popular apps like AnythingLLM, Microsoft VS Code and ComfyUI. Releasing this week, the FLUX.1-schnell image generation model will be available as a NIM microservice, and the popular FLUX.1-dev NIM microservice has been updated to support more RTX GPUs.
Those looking for a simple, no-code way to dive into AI development can tap into Project G-Assist — the RTX PC AI assistant in the NVIDIA app — to build plug-ins to control PC apps and peripherals using natural language AI. New community plug-ins are now available, including Google Gemini web search, Spotify, Twitch, IFTTT and SignalRGB.
Accelerated AI Inference With TensorRT for RTX
Today’s AI PC software stack requires developers to compromise on performance or invest in custom optimizations for specific hardware.
Windows ML was built to solve these challenges. Windows ML is powered by ONNX Runtime and seamlessly connects to an optimized AI execution layer provided and maintained by each hardware manufacturer.
For GeForce RTX GPUs, Windows ML automatically uses the TensorRT for RTX inference library for high performance and rapid deployment. Compared with DirectML, TensorRT delivers over 50% faster performance for AI workloads on PCs.
TensorRT delivers over 50% faster performance for AI workloads on PCs than DirectML. Performance measured on GeForce RTX 5090.
Windows ML also delivers quality-of-life benefits for developers. It can automatically select the right hardware — GPU, CPU or NPU — to run each AI feature, and download the execution provider for that hardware, removing the need to package those files into the app. This allows for the latest TensorRT performance optimizations to be delivered to users as soon as they’re ready.
TensorRT performance optimizations are delivered to users as soon as they’re ready.
TensorRT, a library originally built for data centers, has been redesigned for RTX AI PCs. Instead of pre-generating TensorRT engines and packaging them with the app, TensorRT for RTX uses just-in-time, on-device engine building to optimize how the AI model is run for the user’s specific RTX GPU in mere seconds. And the library’s packaging has been streamlined, reducing its file size significantly by 8x.
TensorRT for RTX is available to developers through the Windows ML preview today, and will be available as a standalone SDK at NVIDIA Developer in June.
Developers can learn more in the TensorRT for RTX launch blog or Microsoft’s Windows ML blog.
Expanding the AI Ecosystem on Windows 11 PCs
Developers looking to add AI features or boost app performance can tap into a broad range of NVIDIA SDKs. These include NVIDIA CUDA and TensorRT for GPU acceleration; NVIDIA DLSS and Optix for 3D graphics; NVIDIA RTX Video and Maxine for multimedia; and NVIDIA Riva and ACE for generative AI.
Top applications are releasing updates this month to enable unique features using these NVIDIA SDKs, including:
LM Studio, which released an update to its app to upgrade to the latest CUDA version, increasing performance by over 30%.
Topaz Labs, which is releasing a generative AI video model to enhance video quality, accelerated by CUDA.
Chaos Enscape and Autodesk VRED, which are adding DLSS 4 for faster performance and better image quality.
Bilibili, which is integrating NVIDIA Broadcast features such as Virtual Background to enhance the quality of livestreams.
NVIDIA looks forward to continuing to work with Microsoft and top AI app developers to help them accelerate their AI features on RTX-powered machines through the Windows ML and TensorRT integration.
Local AI Made Easy With NIM Microservices and AI Blueprints
Getting started with developing AI on PCs can be daunting. AI developers and enthusiasts have to select from over 1.2 million AI models on Hugging Face, quantize it into a format that runs well on PC, find and install all the dependencies to run it, and more.
NVIDIA NIM makes it easy to get started by providing a curated list of AI models, prepackaged with all the files needed to run them and optimized to achieve full performance on RTX GPUs. And since they’re containerized, the same NIM microservice can be run seamlessly across PCs or the cloud.
NVIDIA NIM microservices are available to download through build.nvidia.com or through top AI apps like Anything LLM, ComfyUI and AI Toolkit for Visual Studio Code.
During COMPUTEX, NVIDIA will release the FLUX.1-schnell NIM microservice — an image generation model from Black Forest Labs for fast image generation — and update the FLUX.1-dev NIM microservice to add compatibility for a wide range of GeForce RTX 50 and 40 Series GPUs.
These NIM microservices enable faster performance with TensorRT and quantized models. On NVIDIA Blackwell GPUs, they run over twice as fast as running them natively, thanks to FP4 and RTX optimizations.
The FLUX.1-schnell NIM microservice runs over twice as fast as on NVIDIA Blackwell GPUs with FP4 and RTX optimizations.
AI developers can also jumpstart their work with NVIDIA AI Blueprints — sample workflows and projects using NIM microservices.
NVIDIA last month released the NVIDIA AI Blueprint for 3D-guided generative AI, a powerful way to control composition and camera angles of generated images by using a 3D scene as a reference. Developers can modify the open-source blueprint for their needs or extend it with additional functionality.
New Project G-Assist Plug-Ins and Sample Projects Now Available
NVIDIA recently released Project G-Assist as an experimental AI assistant integrated into the NVIDIA app. G-Assist enables users to control their GeForce RTX system using simple voice and text commands, offering a more convenient interface compared to manual controls spread across numerous legacy control panels.
Developers can also use Project G-Assist to easily build plug-ins, test assistant use cases and publish them through NVIDIA’s Discord and GitHub.
The Project G-Assist Plug-in Builder — a ChatGPT-based app that allows no-code or low-code development with natural language commands — makes it easy to start creating plug-ins. These lightweight, community-driven add-ons use straightforward JSON definitions and Python logic.
New open-source plug-in samples are available now on GitHub, showcasing diverse ways on-device AI can enhance PC and gaming workflows. They include:
Gemini: The existing Gemini plug-in that uses Google’s cloud-based free-to-use large language model has been updated to include real-time web search capabilities.
IFTTT: A plug-in that lets users create automations across hundreds of compatible endpoints to trigger IoT routines — such as adjusting room lights or smart shades, or pushing the latest gaming news to a mobile device.
Discord: A plug-in that enables users to easily share game highlights or messages directly to Discord servers without disrupting gameplay.
Explore the GitHub repository for more examples — including hands-free music control via Spotify, livestream status checks with Twitch, and more.
Companies are adopting AI as the new PC interface. For example, SignalRGB is developing a G-Assist plug-in that enables unified lighting control across multiple manufacturers. Users will soon be able to install this plug-in directly from the SignalRGB app.
SignalRGB’s G-Assist plug-in will soon enable unified lighting control across multiple manufacturers.
Starting this week, the AI community will also be able to use G-Assist as a custom component in Langflow — enabling users to integrate function-calling capabilities in low-code or no-code workflows, AI applications and agentic flows.
The G-Assist custom component in Langflow will soon enable users to integrate function-calling capabilities.
Enthusiasts interested in developing and experimenting with Project G-Assist plug-ins are invited to join the NVIDIA Developer Discord channel to collaborate, share creations and gain support.
Each week, the RTX AI Garage blog series features community-driven AI innovations and content for those looking to learn more about NIM microservices and AI Blueprints, as well as building AI agents, creative workflows, digital humans, productivity apps and more on AI PCs and workstations.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter.
Follow NVIDIA Workstation on LinkedIn and X.
See notice regarding software product information.
#nvidia #microsoft #advance #development #rtxNVIDIA and Microsoft Advance Development on RTX AI PCs
Generative AI is transforming PC software into breakthrough experiences — from digital humans to writing assistants, intelligent agents and creative tools.
NVIDIA RTX AI PCs are powering this transformation with technology that makes it simpler to get started experimenting with generative AI and unlock greater performance on Windows 11.
NVIDIA TensorRT has been reimagined for RTX AI PCs, combining industry-leading TensorRT performance with just-in-time, on-device engine building and an 8x smaller package size for seamless AI deployment to more than 100 million RTX AI PCs.
Announced at Microsoft Build, TensorRT for RTX is natively supported by Windows ML — a new inference stack that provides app developers with both broad hardware compatibility and state-of-the-art performance.
For developers looking for AI features ready to integrate, NVIDIA software development kitsoffer a wide array of options, from NVIDIA DLSS to multimedia enhancements like NVIDIA RTX Video. This month, top software applications from Autodesk, Bilibili, Chaos, LM Studio and Topaz Labs are releasing updates to unlock RTX AI features and acceleration.
AI enthusiasts and developers can easily get started with AI using NVIDIA NIM — prepackaged, optimized AI models that can run in popular apps like AnythingLLM, Microsoft VS Code and ComfyUI. Releasing this week, the FLUX.1-schnell image generation model will be available as a NIM microservice, and the popular FLUX.1-dev NIM microservice has been updated to support more RTX GPUs.
Those looking for a simple, no-code way to dive into AI development can tap into Project G-Assist — the RTX PC AI assistant in the NVIDIA app — to build plug-ins to control PC apps and peripherals using natural language AI. New community plug-ins are now available, including Google Gemini web search, Spotify, Twitch, IFTTT and SignalRGB.
Accelerated AI Inference With TensorRT for RTX
Today’s AI PC software stack requires developers to compromise on performance or invest in custom optimizations for specific hardware.
Windows ML was built to solve these challenges. Windows ML is powered by ONNX Runtime and seamlessly connects to an optimized AI execution layer provided and maintained by each hardware manufacturer.
For GeForce RTX GPUs, Windows ML automatically uses the TensorRT for RTX inference library for high performance and rapid deployment. Compared with DirectML, TensorRT delivers over 50% faster performance for AI workloads on PCs.
TensorRT delivers over 50% faster performance for AI workloads on PCs than DirectML. Performance measured on GeForce RTX 5090.
Windows ML also delivers quality-of-life benefits for developers. It can automatically select the right hardware — GPU, CPU or NPU — to run each AI feature, and download the execution provider for that hardware, removing the need to package those files into the app. This allows for the latest TensorRT performance optimizations to be delivered to users as soon as they’re ready.
TensorRT performance optimizations are delivered to users as soon as they’re ready.
TensorRT, a library originally built for data centers, has been redesigned for RTX AI PCs. Instead of pre-generating TensorRT engines and packaging them with the app, TensorRT for RTX uses just-in-time, on-device engine building to optimize how the AI model is run for the user’s specific RTX GPU in mere seconds. And the library’s packaging has been streamlined, reducing its file size significantly by 8x.
TensorRT for RTX is available to developers through the Windows ML preview today, and will be available as a standalone SDK at NVIDIA Developer in June.
Developers can learn more in the TensorRT for RTX launch blog or Microsoft’s Windows ML blog.
Expanding the AI Ecosystem on Windows 11 PCs
Developers looking to add AI features or boost app performance can tap into a broad range of NVIDIA SDKs. These include NVIDIA CUDA and TensorRT for GPU acceleration; NVIDIA DLSS and Optix for 3D graphics; NVIDIA RTX Video and Maxine for multimedia; and NVIDIA Riva and ACE for generative AI.
Top applications are releasing updates this month to enable unique features using these NVIDIA SDKs, including:
LM Studio, which released an update to its app to upgrade to the latest CUDA version, increasing performance by over 30%.
Topaz Labs, which is releasing a generative AI video model to enhance video quality, accelerated by CUDA.
Chaos Enscape and Autodesk VRED, which are adding DLSS 4 for faster performance and better image quality.
Bilibili, which is integrating NVIDIA Broadcast features such as Virtual Background to enhance the quality of livestreams.
NVIDIA looks forward to continuing to work with Microsoft and top AI app developers to help them accelerate their AI features on RTX-powered machines through the Windows ML and TensorRT integration.
Local AI Made Easy With NIM Microservices and AI Blueprints
Getting started with developing AI on PCs can be daunting. AI developers and enthusiasts have to select from over 1.2 million AI models on Hugging Face, quantize it into a format that runs well on PC, find and install all the dependencies to run it, and more.
NVIDIA NIM makes it easy to get started by providing a curated list of AI models, prepackaged with all the files needed to run them and optimized to achieve full performance on RTX GPUs. And since they’re containerized, the same NIM microservice can be run seamlessly across PCs or the cloud.
NVIDIA NIM microservices are available to download through build.nvidia.com or through top AI apps like Anything LLM, ComfyUI and AI Toolkit for Visual Studio Code.
During COMPUTEX, NVIDIA will release the FLUX.1-schnell NIM microservice — an image generation model from Black Forest Labs for fast image generation — and update the FLUX.1-dev NIM microservice to add compatibility for a wide range of GeForce RTX 50 and 40 Series GPUs.
These NIM microservices enable faster performance with TensorRT and quantized models. On NVIDIA Blackwell GPUs, they run over twice as fast as running them natively, thanks to FP4 and RTX optimizations.
The FLUX.1-schnell NIM microservice runs over twice as fast as on NVIDIA Blackwell GPUs with FP4 and RTX optimizations.
AI developers can also jumpstart their work with NVIDIA AI Blueprints — sample workflows and projects using NIM microservices.
NVIDIA last month released the NVIDIA AI Blueprint for 3D-guided generative AI, a powerful way to control composition and camera angles of generated images by using a 3D scene as a reference. Developers can modify the open-source blueprint for their needs or extend it with additional functionality.
New Project G-Assist Plug-Ins and Sample Projects Now Available
NVIDIA recently released Project G-Assist as an experimental AI assistant integrated into the NVIDIA app. G-Assist enables users to control their GeForce RTX system using simple voice and text commands, offering a more convenient interface compared to manual controls spread across numerous legacy control panels.
Developers can also use Project G-Assist to easily build plug-ins, test assistant use cases and publish them through NVIDIA’s Discord and GitHub.
The Project G-Assist Plug-in Builder — a ChatGPT-based app that allows no-code or low-code development with natural language commands — makes it easy to start creating plug-ins. These lightweight, community-driven add-ons use straightforward JSON definitions and Python logic.
New open-source plug-in samples are available now on GitHub, showcasing diverse ways on-device AI can enhance PC and gaming workflows. They include:
Gemini: The existing Gemini plug-in that uses Google’s cloud-based free-to-use large language model has been updated to include real-time web search capabilities.
IFTTT: A plug-in that lets users create automations across hundreds of compatible endpoints to trigger IoT routines — such as adjusting room lights or smart shades, or pushing the latest gaming news to a mobile device.
Discord: A plug-in that enables users to easily share game highlights or messages directly to Discord servers without disrupting gameplay.
Explore the GitHub repository for more examples — including hands-free music control via Spotify, livestream status checks with Twitch, and more.
Companies are adopting AI as the new PC interface. For example, SignalRGB is developing a G-Assist plug-in that enables unified lighting control across multiple manufacturers. Users will soon be able to install this plug-in directly from the SignalRGB app.
SignalRGB’s G-Assist plug-in will soon enable unified lighting control across multiple manufacturers.
Starting this week, the AI community will also be able to use G-Assist as a custom component in Langflow — enabling users to integrate function-calling capabilities in low-code or no-code workflows, AI applications and agentic flows.
The G-Assist custom component in Langflow will soon enable users to integrate function-calling capabilities.
Enthusiasts interested in developing and experimenting with Project G-Assist plug-ins are invited to join the NVIDIA Developer Discord channel to collaborate, share creations and gain support.
Each week, the RTX AI Garage blog series features community-driven AI innovations and content for those looking to learn more about NIM microservices and AI Blueprints, as well as building AI agents, creative workflows, digital humans, productivity apps and more on AI PCs and workstations.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter.
Follow NVIDIA Workstation on LinkedIn and X.
See notice regarding software product information.
#nvidia #microsoft #advance #development #rtx