


Meet ZebraLogic: A Comprehensive AI Evaluation Framework for Assessing LLM Reasoning Performance on Logic Grid Puzzles Derived from Constraint Satisfaction Problems (CSPs)
www.marktechpost.com
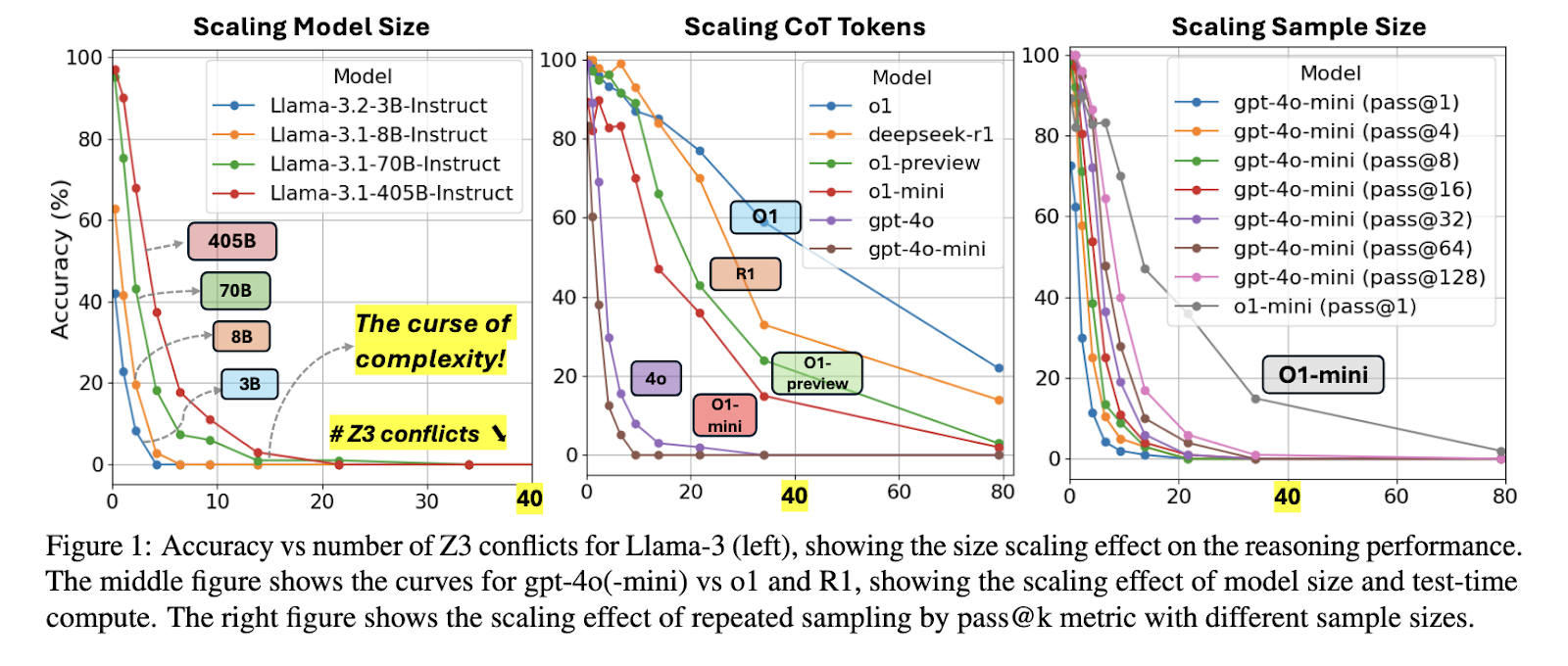
Logical reasoning remains a crucial area where AI systems struggle despite advances in processing language and knowledge. Understanding logical reasoning in AI is essential for improving automated systems in areas like planning, decision-making, and problem-solving. Unlike common-sense reasoning, logical reasoning requires precise rule-based deductions, making it more challenging for LLMs to master.A major obstacle in logical reasoning within AI is handling complex structured problems. Current models struggle with intricate constraints and dependencies, relying on statistical patterns instead of deductive reasoning. This issue becomes more evident as problem complexity increases, resulting in a decline in accuracy. Such limitations pose concerns in high-stakes applications like legal analysis, theorem proving, and scientific modeling, where precise logical deductions are necessary. Researchers aim to address these shortcomings by designing rigorous evaluation frameworks that assess reasoning performance systematically.Traditional logical reasoning methods use constraint satisfaction problems (CSPs), which provide structured evaluation models with controllable difficulty. CSPs enable precise assessment by eliminating training data memorization and ensuring that models rely on actual reasoning capabilities. Logic grid puzzles, a subset of CSPs, are effective testbeds for evaluating structured reasoning in AI. These puzzles require systematic deduction based on defined constraints and have real-world applications in resource allocation, scheduling, and automated planning. However, even the most advanced LLMs struggle with such tasks when complexity increases beyond a certain threshold.A research team from the University of Washington, Allen Institute for AI, and Stanford University introduced ZebraLogic, a benchmarking framework developed to rigorously test LLMs logical reasoning performance. ZebraLogic generates logic puzzles with quantifiable complexity, ensuring a controlled environment for systematic evaluation. The framework prevents data leakage and enables a detailed analysis of an LLMs ability to handle increasingly complex reasoning tasks. ZebraLogic serves as a crucial step toward understanding the fundamental constraints of LLMs in structured reasoning and scaling limitations.The ZebraLogic framework constructs logic puzzles with varying difficulty levels based on two primary complexity measures: search space size and Z3 conflict count, a metric derived from an SMT solver. The study tested leading LLMs, including Metas Llama, OpenAIs o1 models, and DeepSeekR1, and revealed significant accuracy declines as puzzle complexity increased. The framework allowed for a precise assessment of reasoning capabilities across different levels of problem difficulty, making it one of the most structured evaluations of LLMs to date. By systematically varying the constraints, researchers could determine the impact of problem size on logical reasoning performance.Experiments conducted with ZebraLogic exposed the curse of complexity, where LLM performance dropped sharply with increased problem difficulty. The best-performing model, o1, achieved an overall accuracy of 81.0%, while DeepSeekR1 followed closely at 78.7%. However, even these top models struggled when the puzzles search space exceeded 10^7 possible configurations. Medium-complexity puzzles showed a significant decline, with o1 maintaining 92.1% accuracy but dropping to 42.5% on large-scale problems. DeepSeekR1 exhibited similar behavior, excelling in simpler cases but suffering performance losses on more complex tasks. Lower-tier models like Llama-3.1-405B and Gemini-1.5-Pro demonstrated a significant performance gap, reaching 32.6% and 30.5% overall accuracy, respectively.Increasing model size did not significantly mitigate the curse of complexity, as accuracy levels plateaued despite enhanced training. The study tested various methods to improve LLMs reasoning abilities, including Best-of-N sampling and self-verification techniques. Best-of-N sampling improved accuracy slightly, but even with extensive sampling, performance gains remained marginal. Models struggled beyond a search space of 10^9 configurations, suggesting inherent constraints in current architectures. Notably, o1 models generated significantly more hidden reasoning tokens than other LLMs, averaging around 5,144 hidden CoT tokens, compared to GPT-4os 543 tokens. These findings highlight the importance of refining reasoning strategies rather than merely scaling models.ZebraLogics evaluation underscores fundamental limitations in LLMs ability to scale logical reasoning beyond moderate complexity. The findings emphasize the need for alternative approaches, such as enhanced reasoning frameworks and structured logical modeling, rather than relying solely on model expansion. The study presents a crucial benchmark for future AI research, offering insights into the need for improved logical reasoning methodologies. Addressing these challenges will be essential in advancing AI systems that are capable of reliable and scalable logical deduction.Check outthePaper and Project Page.All credit for this research goes to the researchers of this project. Also,dont forget to follow us onTwitterand join ourTelegram ChannelandLinkedIn Group. Dont Forget to join our75k+ ML SubReddit. NikhilNikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.Nikhilhttps://www.marktechpost.com/author/nikhil0980/Princeton University Researchers Introduce Self-MoA and Self-MoA-Seq: Optimizing LLM Performance with Single-Model EnsemblesNikhilhttps://www.marktechpost.com/author/nikhil0980/NYU Researchers Introduce WILDCHAT-50M: A Large-Scale Synthetic Dataset for Efficient LLM Post-TrainingNikhilhttps://www.marktechpost.com/author/nikhil0980/This AI Paper from Meta Introduces Diverse Preference Optimization (DivPO): A Novel Optimization Method for Enhancing Diversity in Large Language ModelsNikhilhttps://www.marktechpost.com/author/nikhil0980/Researchers from University of Waterloo and CMU Introduce Critique Fine-Tuning (CFT): A Novel AI Approach for Enhancing LLM Reasoning with Structured Critique Learning [Recommended] Join Our Telegram Channel
0 Comments
·0 Shares
·52 Views








