Dev snapshot: Godot 4.5 dev 5
Replicube
A game by Walaber Entertainment LLCDev snapshot: Godot 4.5 dev 5By:
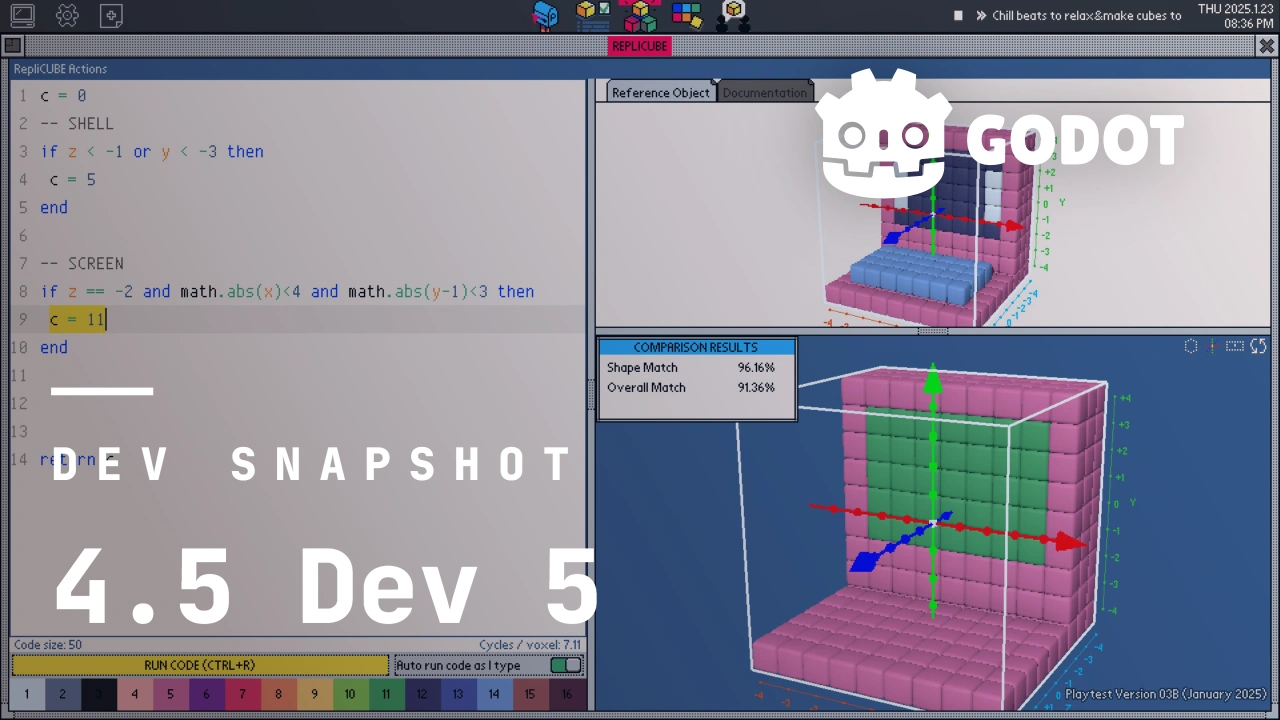
Thaddeus Crews2 June 2025Pre-releaseBrrr… Do you feel that? That’s the cold front of the feature freeze just around the corner. It’s not upon us just yet, but this is likely to be our final development snapshot of the 4.5 release cycle. As we enter the home stretch of new features, bugs are naturally going to follow suit, meaning bug reports and feedback will be especially important for a smooth beta timeframe.Jump to the Downloads section, and give it a spin right now, or continue reading to learn more about improvements in this release. You can also try the Web editor or the Android editor for this release. If you are interested in the latter, please request to join our testing group to get access to pre-release builds.The cover illustration is from Replicube, a programming puzzle game where you write code to recreate voxelized objects. It is developed by Walaber Entertainment LLC. You can get the game on Steam.HighlightsIn case you missed them, see the 4.5 dev 1, 4.5 dev 2, 4.5 dev 3, and 4.5 dev 4 release notes for an overview of some key features which were already in those snapshots, and are therefore still available for testing in dev 5.Native visionOS supportNormally, our featured highlights in these development blogs come from long-time contributors. This makes sense of course, as it’s generally those users that have the familiarity necessary for major changes or additions that are commonly used for these highlights. That’s why it might surprise you to hear that visionOS support comes to us from Ricardo Sanchez-Saez, whose pull request GH-105628 is his very first contribution to the engine! It might not surprise you to hear that Ricardo is part of the visionOS engineering team at Apple, which certainly helps get his foot in the door, but that still makes visionOS the first officially-supported platform integration in about a decade.For those unfamiliar, visionOS is Apple’s XR environment. We’re no strangers to XR as a concept, but XR platforms are as distinct from one another as traditional platforms. visionOS users have expressed a strong interest in integrating with our ever-growing XR community, and now we can make that happen. See you all in the next XR Game Jam!GDScript: Abstract classesWhile the Godot Engine utilizes abstract classes—a class that cannot be directly instantiated—frequently, this was only ever supported internally. Thanks to the efforts of Aaron Franke, this paradigm is now available to GDScript users. Now if a user wants to introduce their own abstract class, they merely need to declare it via the new abstract keyword:abstract class_name MyAbstract extends Node
The purpose of an abstract class is to create a baseline for other classes to derive from:class_name ExtendsMyAbstract extends MyAbstract
Shader bakerFrom the technical gurus behind implementing ubershaders, Darío Samo and Pedro J. Estébanez bring us another miracle of rendering via GH-102552: shader baker exporting. This is an optional feature that can be enabled at export time to speed up shader compilation massively. This feature works with ubershaders automatically without any work from the user. Using shader baking is strongly recommended when targeting Apple devices or D3D12 since it makes the biggest difference there!Before:After:However, it comes with tradeoffs:Export time will be much longer.Build size will be much larger since the baked shaders can take up a lot of space.We have removed several MoltenVK bug workarounds from the Forward+ shader, therefore we no longer guarantee support for the Forward+ renderer on Intel Macs. If you are targeting Intel Macs, you should use the Mobile or Compatibility renderers.Baking for Vulkan can be done from any device, but baking for D3D12 needs to be done from a Windows device and baking for Apple .metallib requires a Metal compiler.Web: WebAssembly SIMD supportAs you might recall, Godot 4.0 initially released under the assumption that multi-threaded web support would become the standard, and only supported that format for web builds. This assumption unfortunately proved to be wishful thinking, and was reverted in 4.3 by allowing for single-threaded builds once more. However, this doesn’t mean that these single-threaded environments are inherently incapable of parallel processing; it just requires alternative implementations. One such implementation, SIMD, is a perfect candidate thanks to its support across all major browsers. To that end, web-wiz Adam Scott has taken to integrating this implementation for our web builds by default.Inline color pickersWhile it’s always been possible to see what kind of variable is assigned to an exported color in the inspector, some users have expressed a keen interest in allowing for this functionality within the script editor itself. This is because it would mean seeing what kind of color is represented by a variable without it needing to be exposed, as well as making it more intuitive at a glance as to what color a name or code corresponds to. Koliur Rahman has blessed us with this quality-of-life goodness, which adds an inline color picker GH-105724. Now no matter where the color is declared, users will be able to immediately and intuitively know what is actually represented in a non-intrusive manner.Rendering goodiesThe renderer got a fair amount of love this snapshot; not from any one PR, but rather a multitude of community members bringing some long-awaited features to light. Raymond DiDonato helped SMAA 1x make its transition from addon to fully-fledged engine feature. Capry brings bent normal maps to further enhance specular occlusion and indirect lighting. Our very own Clay John converted our Compatibility backend to use a fragment shader copy instead of a blit copy, working around common sample rate issues on mobile devices. More technical information on these rendering changes can be found in their associated PRs.SMAA comparison:OffOnBent normal map comparison:BeforeAfterAnd more!There are too many exciting changes to list them all here, but here’s a curated selection:Animation: Add alphabetical sorting to Animation Player.Animation: Add animation filtering to animation editor.Audio: Implement seek operation for Theora video files, improve multi-channel audio resampling.Core: Add --scene command line argument.Core: Overhaul resource duplication.Core: Use Grisu2 algorithm in String::num_scientific to fix serializing.Editor: Add “Quick Load” button to EditorResourcePicker.Editor: Add PROPERTY_HINT_INPUT_NAME for use with @export_custom to allow using input actions.Editor: Add named EditorScripts to the command palette.GUI: Add file sort to FileDialog.I18n: Add translation preview in editor.Import: Add Channel Remap settings to ResourceImporterTexture.Physics: Improve performance with non-monitoring areas when using Jolt Physics.Porting: Android: Add export option for custom theme attributes.Porting: Android: Add support for 16 KB page sizes, update to NDK r28b.Porting: Android: Remove the gradle_build/compress_native_libraries export option.Porting: Web: Use actual PThread pool size for get_default_thread_pool_size.Porting: Windows/macOS/Linux: Use SSE 4.2 as a baseline when compiling Godot.Rendering: Add new StandardMaterial properties to allow users to control FPS-style objects.Rendering: FTI - Optimize SceneTree traversal.Changelog109 contributors submitted 252 fixes for this release. See our interactive changelog for the complete list of changes since the previous 4.5-dev4 snapshot.This release is built from commit 64b09905c.DownloadsGodot is downloading...Godot exists thanks to donations from people like you. Help us continue our work:Make a DonationStandard build includes support for GDScript and GDExtension..NET buildincludes support for C#, as well as GDScript and GDExtension.While engine maintainers try their best to ensure that each preview snapshot and release candidate is stable, this is by definition a pre-release piece of software. Be sure to make frequent backups, or use a version control system such as Git, to preserve your projects in case of corruption or data loss.Known issuesWindows executableshave been signed with an expired certificate. You may see warnings from Windows Defender’s SmartScreen when running this version, or outright be prevented from running the executables with a double-click. Running Godot from the command line can circumvent this. We will soon have a renewed certificate which will be used for future builds.With every release, we accept that there are going to be various issues, which have already been reported but haven’t been fixed yet. See the GitHub issue tracker for a complete list of known bugs.Bug reportsAs a tester, we encourage you to open bug reports if you experience issues with this release. Please check the existing issues on GitHub first, using the search function with relevant keywords, to ensure that the bug you experience is not already known.In particular, any change that would cause a regression in your projects is very important to report.SupportGodot is a non-profit, open source game engine developed by hundreds of contributors on their free time, as well as a handful of part and full-time developers hired thanks to generous donations from the Godot community. A big thank you to everyone who has contributed their time or their financial support to the project!If you’d like to support the project financially and help us secure our future hires, you can do so using the Godot Development Fund.Donate now
#dev #snapshot #godotDev snapshot: Godot 4.5 dev 5
Replicube
A game by Walaber Entertainment LLCDev snapshot: Godot 4.5 dev 5By:
Thaddeus Crews2 June 2025Pre-releaseBrrr… Do you feel that? That’s the cold front of the feature freeze just around the corner. It’s not upon us just yet, but this is likely to be our final development snapshot of the 4.5 release cycle. As we enter the home stretch of new features, bugs are naturally going to follow suit, meaning bug reports and feedback will be especially important for a smooth beta timeframe.Jump to the Downloads section, and give it a spin right now, or continue reading to learn more about improvements in this release. You can also try the Web editor or the Android editor for this release. If you are interested in the latter, please request to join our testing group to get access to pre-release builds.The cover illustration is from Replicube, a programming puzzle game where you write code to recreate voxelized objects. It is developed by Walaber Entertainment LLC. You can get the game on Steam.HighlightsIn case you missed them, see the 4.5 dev 1, 4.5 dev 2, 4.5 dev 3, and 4.5 dev 4 release notes for an overview of some key features which were already in those snapshots, and are therefore still available for testing in dev 5.Native visionOS supportNormally, our featured highlights in these development blogs come from long-time contributors. This makes sense of course, as it’s generally those users that have the familiarity necessary for major changes or additions that are commonly used for these highlights. That’s why it might surprise you to hear that visionOS support comes to us from Ricardo Sanchez-Saez, whose pull request GH-105628 is his very first contribution to the engine! It might not surprise you to hear that Ricardo is part of the visionOS engineering team at Apple, which certainly helps get his foot in the door, but that still makes visionOS the first officially-supported platform integration in about a decade.For those unfamiliar, visionOS is Apple’s XR environment. We’re no strangers to XR as a concept, but XR platforms are as distinct from one another as traditional platforms. visionOS users have expressed a strong interest in integrating with our ever-growing XR community, and now we can make that happen. See you all in the next XR Game Jam!GDScript: Abstract classesWhile the Godot Engine utilizes abstract classes—a class that cannot be directly instantiated—frequently, this was only ever supported internally. Thanks to the efforts of Aaron Franke, this paradigm is now available to GDScript users. Now if a user wants to introduce their own abstract class, they merely need to declare it via the new abstract keyword:abstract class_name MyAbstract extends Node
The purpose of an abstract class is to create a baseline for other classes to derive from:class_name ExtendsMyAbstract extends MyAbstract
Shader bakerFrom the technical gurus behind implementing ubershaders, Darío Samo and Pedro J. Estébanez bring us another miracle of rendering via GH-102552: shader baker exporting. This is an optional feature that can be enabled at export time to speed up shader compilation massively. This feature works with ubershaders automatically without any work from the user. Using shader baking is strongly recommended when targeting Apple devices or D3D12 since it makes the biggest difference there!Before:After:However, it comes with tradeoffs:Export time will be much longer.Build size will be much larger since the baked shaders can take up a lot of space.We have removed several MoltenVK bug workarounds from the Forward+ shader, therefore we no longer guarantee support for the Forward+ renderer on Intel Macs. If you are targeting Intel Macs, you should use the Mobile or Compatibility renderers.Baking for Vulkan can be done from any device, but baking for D3D12 needs to be done from a Windows device and baking for Apple .metallib requires a Metal compiler.Web: WebAssembly SIMD supportAs you might recall, Godot 4.0 initially released under the assumption that multi-threaded web support would become the standard, and only supported that format for web builds. This assumption unfortunately proved to be wishful thinking, and was reverted in 4.3 by allowing for single-threaded builds once more. However, this doesn’t mean that these single-threaded environments are inherently incapable of parallel processing; it just requires alternative implementations. One such implementation, SIMD, is a perfect candidate thanks to its support across all major browsers. To that end, web-wiz Adam Scott has taken to integrating this implementation for our web builds by default.Inline color pickersWhile it’s always been possible to see what kind of variable is assigned to an exported color in the inspector, some users have expressed a keen interest in allowing for this functionality within the script editor itself. This is because it would mean seeing what kind of color is represented by a variable without it needing to be exposed, as well as making it more intuitive at a glance as to what color a name or code corresponds to. Koliur Rahman has blessed us with this quality-of-life goodness, which adds an inline color picker GH-105724. Now no matter where the color is declared, users will be able to immediately and intuitively know what is actually represented in a non-intrusive manner.Rendering goodiesThe renderer got a fair amount of love this snapshot; not from any one PR, but rather a multitude of community members bringing some long-awaited features to light. Raymond DiDonato helped SMAA 1x make its transition from addon to fully-fledged engine feature. Capry brings bent normal maps to further enhance specular occlusion and indirect lighting. Our very own Clay John converted our Compatibility backend to use a fragment shader copy instead of a blit copy, working around common sample rate issues on mobile devices. More technical information on these rendering changes can be found in their associated PRs.SMAA comparison:OffOnBent normal map comparison:BeforeAfterAnd more!There are too many exciting changes to list them all here, but here’s a curated selection:Animation: Add alphabetical sorting to Animation Player.Animation: Add animation filtering to animation editor.Audio: Implement seek operation for Theora video files, improve multi-channel audio resampling.Core: Add --scene command line argument.Core: Overhaul resource duplication.Core: Use Grisu2 algorithm in String::num_scientific to fix serializing.Editor: Add “Quick Load” button to EditorResourcePicker.Editor: Add PROPERTY_HINT_INPUT_NAME for use with @export_custom to allow using input actions.Editor: Add named EditorScripts to the command palette.GUI: Add file sort to FileDialog.I18n: Add translation preview in editor.Import: Add Channel Remap settings to ResourceImporterTexture.Physics: Improve performance with non-monitoring areas when using Jolt Physics.Porting: Android: Add export option for custom theme attributes.Porting: Android: Add support for 16 KB page sizes, update to NDK r28b.Porting: Android: Remove the gradle_build/compress_native_libraries export option.Porting: Web: Use actual PThread pool size for get_default_thread_pool_size.Porting: Windows/macOS/Linux: Use SSE 4.2 as a baseline when compiling Godot.Rendering: Add new StandardMaterial properties to allow users to control FPS-style objects.Rendering: FTI - Optimize SceneTree traversal.Changelog109 contributors submitted 252 fixes for this release. See our interactive changelog for the complete list of changes since the previous 4.5-dev4 snapshot.This release is built from commit 64b09905c.DownloadsGodot is downloading...Godot exists thanks to donations from people like you. Help us continue our work:Make a DonationStandard build includes support for GDScript and GDExtension..NET buildincludes support for C#, as well as GDScript and GDExtension.While engine maintainers try their best to ensure that each preview snapshot and release candidate is stable, this is by definition a pre-release piece of software. Be sure to make frequent backups, or use a version control system such as Git, to preserve your projects in case of corruption or data loss.Known issuesWindows executableshave been signed with an expired certificate. You may see warnings from Windows Defender’s SmartScreen when running this version, or outright be prevented from running the executables with a double-click. Running Godot from the command line can circumvent this. We will soon have a renewed certificate which will be used for future builds.With every release, we accept that there are going to be various issues, which have already been reported but haven’t been fixed yet. See the GitHub issue tracker for a complete list of known bugs.Bug reportsAs a tester, we encourage you to open bug reports if you experience issues with this release. Please check the existing issues on GitHub first, using the search function with relevant keywords, to ensure that the bug you experience is not already known.In particular, any change that would cause a regression in your projects is very important to report.SupportGodot is a non-profit, open source game engine developed by hundreds of contributors on their free time, as well as a handful of part and full-time developers hired thanks to generous donations from the Godot community. A big thank you to everyone who has contributed their time or their financial support to the project!If you’d like to support the project financially and help us secure our future hires, you can do so using the Godot Development Fund.Donate now
#dev #snapshot #godot