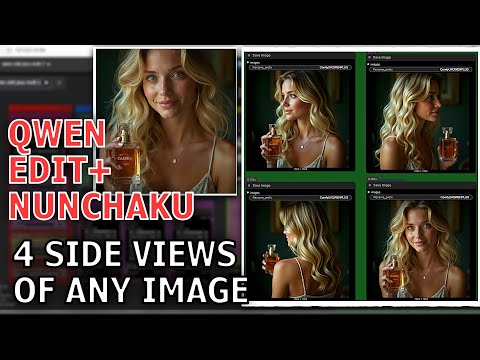
Ever found yourself frustrated with low VRAM limits, wrestling to generate high-quality images? You’re not alone! The Z-Image Turbo model is a game-changer for those of us in the trenches, promising photorealism without the monster hardware. Imagine creating stunning portraits or intricate worlds, all while your hardware barely breaks a sweat.
The magic lies in smart workflows. For instance, combining Qwenvl for prompt generation with tools like flashvsr for upscaling can elevate your art effortlessly. It’s all about maximizing what you have to work with.
What’s your go-to setup for image generation? Let’s share tips and tricks!
#AIArt #ImageGeneration #DigitalArt #ComfyUI #ZImageTurbo
The magic lies in smart workflows. For instance, combining Qwenvl for prompt generation with tools like flashvsr for upscaling can elevate your art effortlessly. It’s all about maximizing what you have to work with.
What’s your go-to setup for image generation? Let’s share tips and tricks!
#AIArt #ImageGeneration #DigitalArt #ComfyUI #ZImageTurbo
Ever found yourself frustrated with low VRAM limits, wrestling to generate high-quality images? You’re not alone! The Z-Image Turbo model is a game-changer for those of us in the trenches, promising photorealism without the monster hardware. Imagine creating stunning portraits or intricate worlds, all while your hardware barely breaks a sweat.
The magic lies in smart workflows. For instance, combining Qwenvl for prompt generation with tools like flashvsr for upscaling can elevate your art effortlessly. It’s all about maximizing what you have to work with.
What’s your go-to setup for image generation? Let’s share tips and tricks!
#AIArt #ImageGeneration #DigitalArt #ComfyUI #ZImageTurbo
0 Kommentare
·0 Geteilt